Azure DevOps pipeline strategy¶
All infrastructure components - AKS clusters, Azure Container Registry (ACR), Argo CD, etc. - are deployed into private networks with Azure Private Link, ensuring no public exposure. Each AKS environment (Dev, Staging, Prod) resides in its own isolated virtual network or subnet, and all necessary Azure services (AKS API server, ACR, Key Vault, Storage, etc.) use Private Endpoints reachable only within those networks . A central hub VNet can be used for shared services (like a jumpbox/Bastion and possibly the CI agent pool), peered to the environment VNets for connectivity. The diagram below illustrates a high-level view of a private AKS deployment with private endpoints for the Kubernetes API, ACR, Storage, and other services :
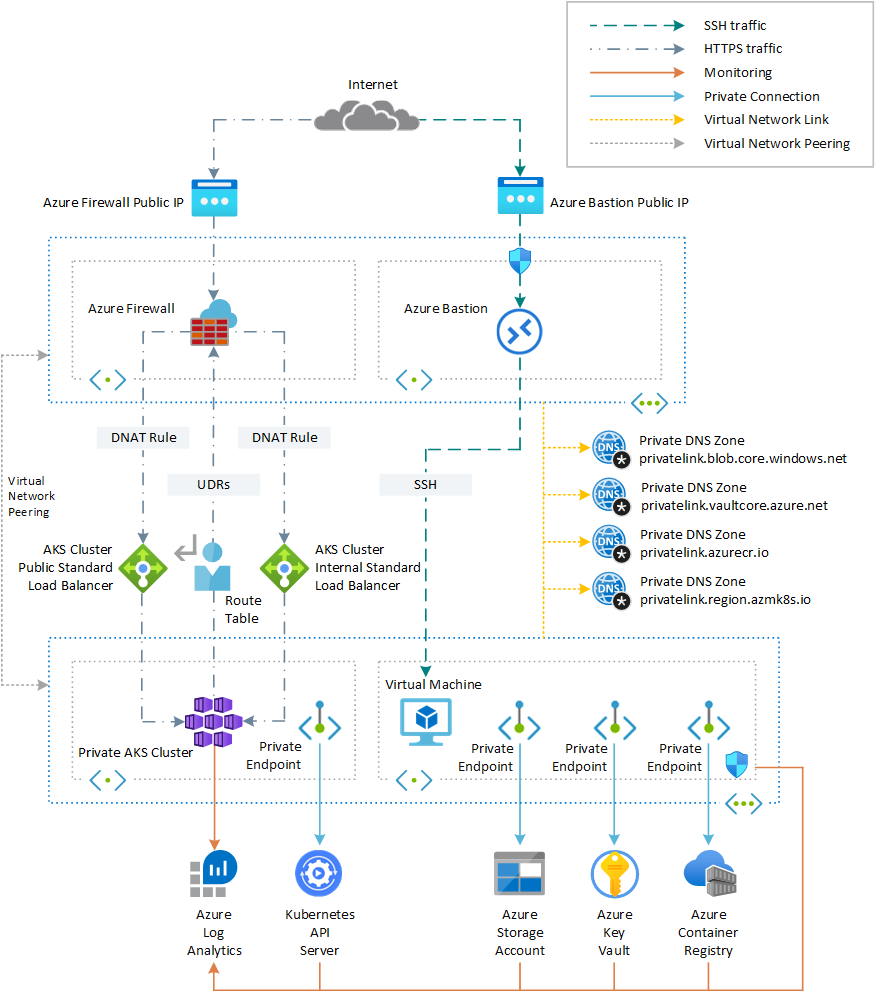 - The AKS API server is accessed via an internal Private Link endpoint (with a private IP address in the VNet). DNS resolution for your-cluster.\<region>.azmk8s.io is handled through a Private DNS Zone linked to the VNet so that the private IP is returned .
- ACR is configured with Premium SKU and a Private Link endpoint in the VNet, plus a Private DNS zone for privatelink.azurecr.io so that pushing/pulling images occurs over the internal network .
- Other services like Azure Key Vault or storage accounts (for Terraform state, etc.) also use private endpoints with appropriate DNS zones.
- No Azure service has a public IP accessible endpoint - all traffic stays within Azure’s private network or goes through controlled egress (for example, an Azure Firewall for outbound traffic filtering as needed for compliance).
- The AKS API server is accessed via an internal Private Link endpoint (with a private IP address in the VNet). DNS resolution for your-cluster.\<region>.azmk8s.io is handled through a Private DNS Zone linked to the VNet so that the private IP is returned .
- ACR is configured with Premium SKU and a Private Link endpoint in the VNet, plus a Private DNS zone for privatelink.azurecr.io so that pushing/pulling images occurs over the internal network .
- Other services like Azure Key Vault or storage accounts (for Terraform state, etc.) also use private endpoints with appropriate DNS zones.
- No Azure service has a public IP accessible endpoint - all traffic stays within Azure’s private network or goes through controlled egress (for example, an Azure Firewall for outbound traffic filtering as needed for compliance).
To perform CI/CD tasks in this locked-down environment, Azure DevOps uses self-hosted build agents connected to the same private network. (Microsoft-hosted agents cannot reach private endpoints on your VNet .) A common pattern is to run a self-hosted agent on a VM (or as a container) inside the hub VNet or even within one of the AKS clusters. The agent’s network is peered with the AKS and ACR VNets so it can contact the private AKS API and ACR endpoints . Using a single Azure DevOps YAML pipeline (with multiple stages) and this private agent, we can provision infrastructure, build and push container images, and deploy workloads via GitOps across all three environments in sequence.
Pipeline workflow (Multistage)¶
We configure a multi-stage YAML pipeline in Azure DevOps that encompasses CI (build) and CD (deploy to each environment) using a GitOps model. The pipeline is triggered by changes in the application repository (e.g. code or manifest updates on the main branch) and orchestrates the following stages:
- Build stage (CI) - This stage builds the application and container image, then prepares Kubernetes manifest files for deployment. For example, a .NET application is compiled and packaged, then a Docker image is built and pushed to the private ACR. The pipeline uses the self-hosted agent to log in to ACR (via Azure CLI using managed identity or a short-lived token) and push the image. After pushing, the Kubernetes deployment manifests are updated to reference the new image tag. (In one approach, a token placeholder in the manifest (e.g. __Build.BuildId__) is replaced with the actual build ID or version to pin the image tag .) The manifest files for all environments are collected as a pipeline artifact for use in later stages.
- Deployment stage - Dev - After a successful build, the pipeline automatically deploys to the Dev AKS cluster. Deployment is done via GitOps: the pipeline takes the manifest files (from the artifact) corresponding to the Dev environment and commits them to a GitOps configuration repository (or branch) designated for Dev. We typically maintain a separate deployment repo (or separate folder/branch) that ArgoCD watches. Using a tool like Kustomize, we keep a common base set of manifests and environment-specific overlays (Dev/Staging/Prod) in the source repo. The pipeline will combine the base + Dev overlay and commit the result to the GitOps repo . This Git commit represents the desired state for Dev, and triggers ArgoCD to sync the Dev cluster. The Dev stage in the pipeline can be fully automated (no manual approval), enabling rapid continuous integration of new changes into the Dev cluster.
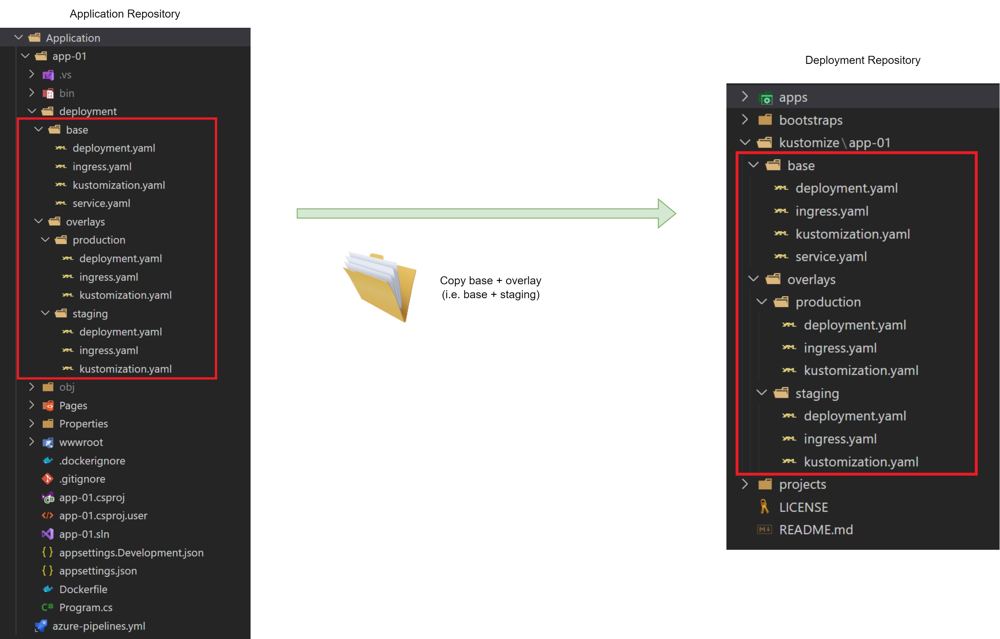
- Deployment stage - Staging - Once Dev deployment is verified (e.g. tests pass), the pipeline can promote the release to Staging. The Staging stage will fetch the same artifact (or reuse the source manifests) but apply the Staging overlay. It then commits the base + Staging manifests to the GitOps repo (in a separate path or branch for Staging) . ArgoCD in the staging cluster (or ArgoCD instance managing multiple clusters) detects the commit and applies the changes to the Staging AKS cluster. In Azure Pipelines, this stage is defined as a deployment job targeting a “Staging” environment, which allows configuration of approvals before the stage runs . Typically, you would enable a manual approval or quality gate check - for example, require a team lead to approve promoting the release to Staging (as per change management policies).
- Deployment stage - Production - Finally, the pipeline promotes the release to Prod (again using GitOps). The Prod stage, also a deployment job tied to a “Production” environment in Azure DevOps, will wait on a manual approval (and any additional checks) before execution . Upon approval, it commits the base + Production overlay manifests to the production GitOps repo/branch. ArgoCD then syncs the Prod AKS cluster to match. This multi-stage promotion flow ensures an audited, gradual rollout: changes deploy to Dev, then Staging, then Prod, with control points in between. Only the GitOps repo reflects the deployed state - each environment’s actual cluster config is driven from what’s committed there, not from ad-hoc kubectl applies. This approach provides a clear separation of concerns: the application team manages app code and base manifests in one repo, while the pipeline automates promotion of vetted configs into the live deployment repo for ArgoCD.
Diagram - GitOps deployment flow: The image below shows how a single pipeline uses a GitOps approach across environments. The application’s repository (left) contains a deployment folder with a Kustomize base and overlays for each environment (Dev/Staging/Prod). During the pipeline, for each environment stage, the base plus that environment’s overlay is copied into the separate deployment repository (right) which ArgoCD monitors. Only the manifests in the deployment repo (with environment-specific values and image tags) represent what is running in the cluster . This ensures a single source of truth for cluster configuration, and the pipeline automates updating that source of truth for each environment.
Private networking and security best practices¶
Because all resources are private, special care is taken for connectivity and security in the pipeline architecture:
- Self-hosted agents in private network: As noted, use an Azure DevOps self-hosted agent that runs inside the private network (for example, on a VM in the hub VNet). This agent should have network access to all required private endpoints. For instance, the agent’s VNet must be peered with the AKS cluster’s VNet and with the ACR’s Private Link VNet so that myregistry.azurecr.io (which resolves to a private IP) is reachable . The agent can also reach the AKS API server’s private endpoint. If multiple environment VNets are isolated, you might deploy one agent per environment VNet or use a hub-and-spoke network topology with the agent in the hub that peers to all. Ensure the private DNS zones for privatelink.azurecr.io, privatelink.\<region>.azmk8s.io, etc., are linked to the agent’s VNet so that DNS resolution for private endpoints works from the agent. This networking setup is critical - without it, the pipeline cannot pull/push images or talk to AKS. (For additional security, restrict the agent VM’s NSG to only allow necessary egress, and consider locking down outbound internet except to Azure DevOps service tags or required endpoints.)
- Managed identities for Azure authentication: Use Azure AD managed identities wherever possible in the pipeline to avoid long-lived credentials. For example, instead of storing a service principal secret for Terraform or az CLI, the self-hosted agent (if it’s an Azure VM) can utilize its system-assigned managed identity or a user-assigned identity. Azure DevOps now supports Workload Identity Federation with OIDC, which allows the pipeline to obtain an Azure AD token for a managed identity without any secret . This means the pipeline can run az login --identity (on a managed-identity-enabled VM) or use an OIDC-based Service Connection, and Terraform or Azure CLI commands will authenticate transparently . The AKS clusters themselves should use Managed Identity for cluster resources (AKS supports assigning a managed identity to handle cloud resources like load balancers, disks, etc., instead of using the deprecated service principal). All Azure resource deployments in Terraform can also use managed identities (the AzureRM Terraform provider can pick up the managed identity credentials from the environment) - this aligns with the principle of secretless infrastructure deployment.
- ACR Authentication: Grant the pipeline’s identity push/pull access to ACR (e.g. the agent VM’s managed identity or a dedicated AAD app with AcrPush role on the registry). The pipeline can then authenticate to ACR using Azure CLI or Docker login via Azure AD. For instance, after az login --identity, running az acr login -n \<registry> uses the identity’s Azure AD token to log in, so that docker push can be done securely without needing an ACR admin password or access key. On the cluster side, ensure each AKS cluster’s kubelet identity (or the node MSI) has pull rights on ACR, or enable ACR integration via AKS so pods can pull images from the private registry over the private link . This setup ensures that even container image distribution is fully within private networks and authenticated via AD.
- ArgoCD network access: ArgoCD is deployed inside AKS (likely in all three clusters, or a central ArgoCD managing multiple clusters). ArgoCD itself should also be configured with private network access only. For example, do not expose the ArgoCD web UI with a public LoadBalancer; instead use an Internal Load Balancer service or simply access it via Kubernetes port-forward/Bastion. If ArgoCD needs to pull manifests from an Azure DevOps Git repository, ensure the cluster has egress access to Azure DevOps Services (DevOps is public SaaS; you may allow specific outbound traffic to dev.azure.com or set up a private agent within the cluster to proxy). Storing the GitOps config in an Azure Repo or GitHub is fine as long as ArgoCD can reach it - you might use a proxy or repository credentials with limited scope. The Git repository URL and a PAT/SSH key (stored in a Kubernetes secret) can be configured in ArgoCD so that it can git pull the manifests. This communication should be the only outbound path - and you can restrict it via an egress firewall/NAT to only the Git server. (Alternatively, some setups use a private mirror of the git repo reachable inside the network.)
- Least privilege & network segmentation: Each stage of the pipeline and each component runs with the minimum privileges needed. The self-hosted agent VM’s managed identity should be granted only the Azure RBAC roles it needs (e.g., Contributor or specific resource scope for Terraform deployments, AcrPush for ACR, reader for maybe AKS if needed to fetch credentials - though az aks get-credentials is done via Azure API which the identity can be permitted to call). ArgoCD’s Kubernetes RBAC permissions should be scoped to only the namespaces it needs to manage in the cluster. We also recommend using Azure AD RBAC for AKS (Azure RBAC integration) to control who can get access to the cluster or perform actions - for instance, the ArgoCD application controller might have a dedicated Kubernetes service account with limited privileges to create resources in specific namespaces. Additionally, each environment (Dev/Staging/Prod) is isolated; for example, use separate resource groups and separate credentials/permissions for each environment’s resources. This can prevent a breach in a lower environment from affecting production. In the Azure DevOps pipeline, use environment approvals and checks (built-in feature) to enforce that promotion to prod requires authorization and that pipeline stages only run in the context of the proper environment resources .
- Secure secret management: Eliminate plain-text secrets in the pipeline. Any sensitive values (e.g., a GitOps PAT token if needed, or certain config secrets) should be stored in Azure Key Vault or Azure DevOps secure variable groups. Azure DevOps pipeline can integrate with Key Vault to fetch secrets at runtime. For example, if ArgoCD needs bootstrap credentials or if Terraform needs certain passwords, keep those in Key Vault (which also has a private endpoint) and use managed identity for the pipeline to access Key Vault. This approach is aligned with ISO27001 control objectives for cryptographic key management and secret handling.
- Logging and monitoring: Enable diagnostics on all components for audit trails. AKS can send diagnostics to Azure Monitor/Log Analytics (which, in a private setup, would also be accessed via private link). ArgoCD logs should be collected (e.g., through AKS container logging) for audit of deployments. Azure DevOps provides build and release logs - ensure these are retained as per compliance needs. You might also integrate Azure Monitor Container Insights and Security Center (Defender for Cloud) for the clusters to detect any anomalies.
By implementing these network and identity best practices, the CI/CD pipeline operates entirely within a closed network, uses Azure AD for auth (avoiding static creds), and restricts both network traffic and permissions to reduce risk. This design meets high security standards and is prepared for compliance audits.
Argo CD configuration and GitOps model¶
Using ArgoCD for GitOps deployment ensures that the actual state of the AKS clusters is always derivable from source control (the GitOps repo). For a secure setup in this scenario:
- ArgoCD installation: ArgoCD can be installed on each cluster (Dev, Staging, Prod) or a single central ArgoCD instance managing multiple clusters. In either case, installation should be done via IaC. For example, include an ArgoCD Helm chart release in your Terraform modules or have the pipeline apply the ArgoCD manifests after cluster creation. ArgoCD will run with cluster-internal access only. If using Terraform, you can automate ArgoCD deployment (e.g., using the official Argo Helm chart via Terraform’s Helm provider) as part of the infrastructure provisioning . This means as soon as a cluster is created, ArgoCD is installed and can be pointed to the correct Git repo path for that environment.
- Private repo access: Configure ArgoCD to authenticate to the GitOps repository (which could be an Azure DevOps Repo or a private GitHub repo). Typically, you create a read-only PAT (Personal Access Token) or SSH key and add it to ArgoCD as a secret (argocd-secret in the argocd namespace) so that ArgoCD can periodically pull the repository. Since ArgoCD in this setup cannot reach the public internet freely, ensure that the cluster’s network allows egress to the Git host. One way is to use an egress firewall/NAT that only allows traffic to specific endpoints (e.g., Azure DevOps endpoint URLs). Another is to host the Git repo on a VM or service inside the Azure network, but using Azure DevOps with selective egress is usually fine. ArgoCD sync intervals and webhook triggers (if applicable) should be tuned - e.g., Azure DevOps can send a webhook to ArgoCD on new commit, but that requires ArgoCD’s API to be reachable; in a private setup you might rely on Argo’s polling or have a private connectivity method for webhooks.
- Azure AD SSO for ArgoCD: To avoid local accounts and to leverage corporate identity (with MFA and PIM controls), integrate ArgoCD’s UI authentication with Azure Active Directory. ArgoCD supports OIDC SSO. You’d register ArgoCD as an app in Azure AD, then configure ArgoCD’s argocd-cm ConfigMap with OIDC settings (client ID, issuer URL, etc.). After this, users can log into ArgoCD via Azure AD credentials . This provides unified authentication - users use their AAD accounts (which likely have MFA enforced) to access ArgoCD, and you can use AAD groups to assign roles in ArgoCD. For example, create AAD groups for “ArgoCD Admins” and “ArgoCD ReadOnly”, then map those groups to ArgoCD RBAC roles (in ArgoCD’s RBAC config map). This way, you avoid maintaining separate ArgoCD passwords and you automatically satisfy enterprise requirements for centralized identity management. ArgoCD with AAD means no broad Argo admin password floating around - authentication is as secure as your Azure AD (which likely includes MFA, conditional access, etc.).
- Role-based access control (RBAC): With ArgoCD on AAD, you can enforce that only specific people (in specific AAD groups) can sync or override deployments. Day-to-day, ArgoCD will sync automatically, so manual intervention is rarely needed except for troubleshooting or sync waves. Those actions (like manually syncing an application or editing a config through ArgoCD UI) should be limited to privileged users. PIM can be used here: for example, require that membership in the “ArgoCD Admin” AAD group is eligible and must be activated via Azure AD PIM for a limited time. This means even if someone is an Argo admin, they have to perform a just-in-time elevation (with approval if configured) to use that role . This meets the principle of just-in-time access - nobody has standing admin privileges in ArgoCD or the cluster. Azure AD PIM provides audit logs and requires MFA on role activation , further securing these operations. In practice, your team might designate a few ops engineers who can elevate to ArgoCD admins when needed (with all actions being logged).
- Sync and multi-cluster config: Each environment’s cluster will have either its own ArgoCD instance or be managed by a centralized ArgoCD (running perhaps in the hub or in the prod cluster managing others as “managed clusters”). In a multi-cluster setup, ArgoCD uses Kubernetes contexts and certificates to talk to the other clusters - you’d store the cluster credentials (kubeconfig contexts or tokens) in ArgoCD so it can apply manifests to dev and staging clusters. Those credentials should be set up carefully (only give ArgoCD the minimal permissions on those clusters, possibly just enough to create resources in allowed namespaces). If ArgoCD is per-cluster, then each ArgoCD only manages its local cluster (which can simplify permissions). Either way, isolate the config so that, for example, Dev ArgoCD can’t accidentally sync to Prod. Usually, separate Git folders or projects are used per environment and ArgoCD Applications are defined accordingly.
- Bootstrap and app of apps: Consider using ArgoCD to also manage cluster add-ons via a bootstrap config (sometimes called an “App of Apps” pattern). For instance, you might have ArgoCD itself installed via Terraform, but then ArgoCD could deploy common add-ons like ingress controllers, cert managers, etc., by pointing to a bootstrap git directory. This ensures even core cluster components are under GitOps deployment. This is not strictly required, but a nice way to ensure the entire cluster state is declarative and auditable.
In summary, ArgoCD’s GitOps model provides a pull-based, declarative deployment process: the pipeline’s job is simply to update Git with desired state, and ArgoCD takes care of applying it to AKS. The use of private endpoints and Azure AD SSO for ArgoCD guarantees that the configuration and management plane of Kubernetes is secured - only authorized users can push changes (via Git or via ArgoCD UI with AAD auth), and clusters only pull from trusted sources. This setup is in line with modern Zero Trust DevOps: no direct access to production clusters from the internet, all changes funnel through Git with proper review, and all credentials are managed by AAD.
Azure DevOps pipeline implementation (YAML snippets)¶
Below are examples of how to implement key parts of the single Azure DevOps pipeline using YAML. The pipeline definition resides in your application repo (infrastructure pipelines can be in an infra repo). It uses variables and templates to avoid repetition where possible. We assume the Azure DevOps project has service connections or other settings set up for the resources (for instance, an Azure service connection that uses the VM’s managed identity via OIDC, and a Git service connection for the deployment repo).
1. Terraform infrastructure stage (Excerpt): Uses the AzureCLI task to run Terraform for each environment. Managed identity auth is used by relying on az login --identity. We use separate tfvar files per environment and a backend config that isolates state (e.g., using a Key Vault-backed storage account, one state file per env). In practice, you might parameterize the environment and reuse the job for dev/staging/prod or have separate jobs. Here’s a snippet for one environment (Dev) stage:
stages:
- stage: Infra_Dev
displayName: "Provision Dev Infrastructure"
jobs:
- job: terraformDev
pool:
name: SelfHostedAgents # Use self-hosted agent pool
steps:
- task: AzureCLI@2
displayName: "Terraform Init & Apply (Dev)"
inputs:
azureSubscription: "<Azure Service Connection Name>"
scriptType: bash
scriptLocation: inlineScript
# Ensure the service connection is set to use workload identity or MSI
inlineScript: |
# Login using the managed identity (if running on an Azure VM with system-assigned identity)
az login --identity || exit 1
cd terraform/env/dev
terraform init -backend-config="key=terraform.state/dev.tfstate"
terraform plan -var-file="dev.tfvars"
terraform apply -auto-approve -var-file="dev.tfvars"
In this snippet, the pipeline uses a service connection that is configured for Workload identity federation, allowing AzureCLI@2 to run without secrets (the az login --identity will work if the agent has an identity and the service connection is set up appropriately) . We change directory to the Terraform config for the Dev environment and run init/plan/apply. This would create or update resources like the dev AKS, dev ACR, etc. (It’s assumed that dev.tfvars contains environment-specific values such as names and IP ranges, and the Terraform code uses those to instantiate modules.)
You would replicate similar jobs or steps for staging and prod - possibly as separate stages Infra_Staging and Infra_Prod, or as jobs under one Infra stage, depending on whether you want to apply them in sequence automatically or only on demand. Often, infrastructure for higher environments is applied manually (via pipeline with approval) rather than on every code release. You can utilize Azure DevOps Environments for the infrastructure stages as well, and protect them with approvals (e.g., require ops team approval before running Terraform in Prod).
2. Build and push container stage: For the CI build, Azure Pipelines can use a Docker task or script. Below is a snippet using Docker to build and push an image to ACR. This assumes the agent can resolve the ACR private endpoint and has permission to push. We use the Azure CLI to authenticate with the managed identity and then docker commands:
- stage: Build
displayName: "Build and Push Container"
jobs:
- job: buildImage
pool:
name: SelfHostedAgents
steps:
- script: |
az login --identity
az acr login --name $(ACR_NAME)
displayName: "Azure Login (Managed Identity) and ACR Login"
- task: Docker@2
displayName: "Build Image"
inputs:
command: build
Dockerfile: "src/Dockerfile"
tags: "$(Build.BuildId)"
containerRegistry: "ACR_Service_Connection" # if using a service connection for ACR
repository: "$(ACR_NAME).azurecr.io/myapp"
- task: Docker@2
displayName: "Push Image"
inputs:
command: push
tags: "$(Build.BuildId)"
containerRegistry: "ACR_Service_Connection"
repository: "$(ACR_NAME).azurecr.io/myapp"
- bash: |
# Prepare manifests for deployment
# e.g., copy base + overlays to a folder and substitute image tag
cp -r k8s-manifests/ $(Build.ArtifactStagingDirectory)/
# Replace image tag placeholder in manifests with the Build ID
find $(Build.ArtifactStagingDirectory) -type f -name '*.yaml' -print0 | xargs -0 sed -i "s/__IMAGE_TAG__/$(Build.BuildId)/g"
displayName: "Prepare Kubernetes manifests"
- publish: $(Build.ArtifactStagingDirectory)
artifact: manifests
In the above, we first ensure Azure CLI is logged in via the identity and logs into ACR (this step might be optional if using the Docker task with a proper service connection that already has credentials). We then use the Docker task to build and push the image. We tag the image with the unique build ID (or a version number). Then we copy the Kubernetes manifest templates to the artifact staging directory and replace a placeholder __IMAGE_TAG__ with the actual tag (the build ID) . We publish the manifests artifact so that subsequent stages can retrieve the exact manifests to deploy.
Note: You could also do image scanning here (e.g., run Trivy or Aqua scanner as a step after building but before pushing). This is recommended to ensure no high vulnerabilities are introduced into ACR - failing the build if critical issues are found will align with security best practices.
3. Deploy (GitOps) stages: For the Staging and Production stages, we use deployment jobs with environment approvals. We also use the Azure DevOps Git repository resource to push changes to the GitOps repo. For example:
resources:
repositories:
- repository: deploymentRepo
type: git
name: ContosoOrg/aks-gitops-config # pointing to the GitOps repo (could be Azure DevOps or GitHub)
ref: main
trigger: none # no auto trigger from this repo
...
- stage: Deploy_Staging
displayName: "Deploy to Staging (GitOps Commit)"
dependsOn: Build
condition: succeeded()
jobs:
- deployment: deployStaging
environment: "AKS-Staging" # Azure DevOps environment with approval policies
pool:
name: SelfHostedAgents
strategy:
runOnce:
deploy:
steps:
- download: manifests
artifact: manifests
- bash: |
# Use git to sync manifests to deployment repo (staging overlay)
git config --global user.email "[email protected]"
git config --global user.name "AzurePipeline"
git clone $(deploymentRepo.gitUrl) repo # clone the deployment repo
cd repo
git checkout -B staging # use staging branch or folder
cp -R $(Pipeline.Workspace)/manifests/base .
cp -R $(Pipeline.Workspace)/manifests/overlays/staging ./overlays/staging
git add .
git commit -m "Deploy $BUILD_BUILDID to Staging"
git push origin staging
env:
# Use Azure DevOps OAuth token to authenticate push (if using Azure Repos)
SYSTEM_ACCESSTOKEN: $(System.AccessToken)
displayName: "Commit manifests to GitOps repo (staging)"
In this snippet, the Deploy_Staging stage depends on the Build stage’s artifact. It downloads the manifests artifact, then uses a script to commit the appropriate manifests to the staging branch of the GitOps repository. We configured a repository resource named deploymentRepo for this purpose - Azure DevOps will handle the credentials. If this repo is an Azure Repo in the same project, we can use $(System.AccessToken) (with permission enabled in the pipeline settings) to push. If it’s external (GitHub), a service connection or PAT would be needed. The environment AKS-Staging is used to enforce that a manual approval is required (if configured in Azure DevOps > Pipelines > Environments > AKS-Staging). After this stage runs, the ArgoCD on the Staging cluster notices the commit and deploys the changes.
The production stage would be almost identical, but targeting environment: "AKS-Prod" and perhaps a prod branch or folder. It would typically have a manual approval before it runs (enforced by Azure DevOps environment checks) . The commit message and branch would be for production. For example:
- stage: Deploy_Prod
displayName: "Deploy to Production (GitOps Commit)"
dependsOn: Deploy_Staging
condition: succeeded()
jobs:
- deployment: deployProd
environment: "AKS-Prod"
pool:
name: SelfHostedAgents
strategy:
runOnce:
deploy:
steps:
- download: manifests
artifact: manifests
- bash: |
cd repo # assuming repo already cloned or clone anew as above
git checkout -B production
# copy base + production overlay
cp -R $(Pipeline.Workspace)/manifests/base .
cp -R $(Pipeline.Workspace)/manifests/overlays/production ./overlays/production
git add .
git commit -m "Deploy $BUILD_BUILDID to Production"
git push origin production
env:
SYSTEM_ACCESSTOKEN: $(System.AccessToken)
This stage would wait for approval and then perform the commit to the production config. The use of deployment jobs not only allows approvals, but also integrates with Azure DevOps Environments for tracking deployments and possibly linking to Kubernetes resource views.
Key points in this pipeline setup:¶
- We re-use a single pipeline definition to handle all three environments in a controlled way (instead of maintaining separate pipelines per environment). Each environment’s deployment is a stage in the pipeline, which promotes consistency and easier maintenance .
- Approvals and checks are built-in between stages, satisfying any segregation of duties requirement (e.g., a different person can review/approve the Prod stage) .
- All secrets (like the System.AccessToken or any PAT) are handled securely by Azure DevOps - we’re not hard-coding credentials in the YAML.
- The pipeline uses YAML (as opposed to classic UI pipelines) which means it’s in code and version-controlled. Changes to the pipeline itself can go through pull request reviews. This is important for compliance - the pipeline as code can be audited and tested like any other code .
- The Terraform steps could also be split into a separate pipeline (triggered on changes to infrastructure code). Many organizations separate infra deployment from app deployment. In that case, you’d have an “Infra Pipeline” that maybe runs on a schedule or on PR merge for Terraform changes, and a “App Pipeline” as shown above for the continuous app deployments. The question’s scope suggests using one pipeline for simplicity, but it’s worth noting that in practice you might not run Terraform on every app release - you run it when you need to update infrastructure. Still, the pipeline YAML snippets above demonstrate how to include it if desired.
Terraform module structure and environment organization¶
Organizing Terraform code for multiple environments is critical. A recommended approach is to modularize the infrastructure and separate environment-specific configurations. Use a folder structure that isolates each environment’s state and variables while reusing common modules for the actual resource definitions. For example:
├── terraform/
│ ├── modules/
│ │ ├── aks/
│ │ │ └── main.tf # Terraform code to create AKS (cluster, node pools, etc.)
│ │ ├── acr/
│ │ │ └── main.tf # Terraform code to create ACR (with private endpoint)
│ │ ├── network/
│ │ │ └── main.tf # VNet, subnets, peerings, etc.
│ │ └── argocd/
│ │ └── main.tf # (optional) Terraform code to install ArgoCD via Helm
│ └── env/
│ ├── dev/
│ │ ├── main.tf # Calls modules for dev environment
│ │ ├── variables.tf # Variables specific to dev (if any)
│ │ └── dev.tfvars # Values for dev (if using tfvars)
│ ├── staging/
│ │ └── {...}
│ └── prod/
│ └── {...}
In this structure, the modules folder contains reusable Terraform modules for each major component (network, AKS, ACR, etc.). For example, the aks module might define an azurerm_kubernetes_cluster resource with parameters for name, node count, private API enablement, etc. The acr module defines an azurerm_container_registry and perhaps the azurerm_private_endpoint to the registry. Each module can be versioned and tested independently. Then under env, we have a folder per environment. In each environment’s Terraform config (say env/dev/main.tf), we instantiate the modules with environment-specific parameters. For instance:
# env/dev/main.tf
module "network" {
source = "../../modules/network"
location = var.location
vnet_name = "dev-vnet"
address_space = "10.10.0.0/16"
# other networking settings
}
module "aks" {
source = "../../modules/aks"
location = var.location
cluster_name = "dev-aks"
vnet_subnet_id = module.network.aks_subnet_id
enable_private_cluster = true
enable_arena = true
dns_service_ip = "10.0.0.10" # example
# ... pass other needed variables
}
module "acr" {
source = "../../modules/acr"
name = "devContainerRegistry"
sku = "Premium"
network_subnet_id = module.network.private_endpoints_subnet_id
link_dns_zone = true
}
# possibly module "argocd" to bootstrap ArgoCD via Helm chart
The dev.tfvars can specify values for variables like var.location (region) or any differences like sizes (# of nodes, etc.). This pattern ensures that environments are consistently built (using the same modules) but with isolated configurations. It prevents cross-environment impact - running terraform apply in the dev folder touches only dev’s resources, etc. “It’s essential to isolate the configurations for each environment to prevent unintended changes that could affect stability” . Each environment can even have its own remote state file (for example, use an Azure Storage backend with key env/dev/terraform.tfstate for dev, etc., as shown in the snippet above). This separation aligns with Terraform best practices for multi-env deployments (using either separate workspaces or separate directories; directories with tfvars as shown is straightforward ).
Using modules also simplifies compliance: you can enforce certain settings in modules (for example, the AKS module can default enable_private_cluster = true and require certain tags on all resources, etc.). This ensures every environment’s cluster meets baseline security (no one can accidentally create a public AKS in prod, for instance, if the module doesn’t allow it or defaults it to private).
Additionally, treat your Terraform code like code (stored in a repo, with PR reviews). The Azure DevOps pipeline can run terraform plan on PRs to show a preview of changes, which should be reviewed by ops team members before merging. Upon merge, the pipeline runs terraform apply. This process itself is a good practice meeting ISO27001 change management controls - infrastructure changes are tracked, reviewed, and auditable .
State and secrets: Use remote state storage with access control (Azure Blob Storage with Private Endpoint and Azure AD auth, for example) so that state is not locally stored in the pipeline agent. Enable state locking (the Azure Blob backend supports it) to prevent concurrent changes. Any sensitive output (like keys or passwords Terraform generates) can be stored in Azure Key Vault rather than outputting to plain text. The pipeline can retrieve from Key Vault if needed.
Testing and rollback: You might also incorporate a testing step after Terraform deploys (e.g., use azure-cli or kubectl to smoke test that the cluster is reachable, or run Terraform validations). In case of an issue, because everything is codified, you can roll back changes by reverting the code in Git (GitOps for apps and Terraform for infra). Having consistent modules makes rollbacks or recreations more reliable.
Compliance considerations (ISO 27001, DORA, NIS2)¶
This pipeline and deployment approach is designed with strict compliance in mind. Here’s how it addresses key requirements of ISO27001 and European regulations like DORA and NIS2:
- Change management and traceability: All changes to both infrastructure and workloads are done through code (Terraform, Kubernetes manifests) and go through a pipeline with approvals. This creates an audit trail for every change. ISO27001 requires controlled changes and separation of duties; our multi-stage pipeline with approvals and logging fulfills this. Azure DevOps maintains logs of who approved a deployment, what code was changed, and when - providing evidence for auditors. Git history combined with pipeline logs can reconstruct the sequence of events for any deployment, satisfying ISO27001 A.12 (change management) controls. Moreover, DORA emphasizes operational resilience and governance - having IaC and GitOps means you can rebuild environments quickly in disaster recovery scenarios, and all changes are versioned (improving recoverability and integrity).
- Least privilege & JIT access: Using Azure AD and PIM ensures that no one (not even developers or admins) has standing privileged access to production. All admin actions (like approving a prod deployment or accessing ArgoCD/AKS) require just-in-time elevation with MFA . NIS2 and DORA mandate strong access control; for example, NIS2 Article 21 specifically calls for multi-factor authentication for administrative access . In this design, Azure AD enforces MFA for signing into Azure DevOps and ArgoCD (via AAD SSO), and PIM can enforce MFA on role activation as well . No credentials are shared; everything leverages Azure AD tokens and managed identities. This significantly reduces the risk of credential leakage - an important factor for ISO27001 (A.9 Access Management) and DORA’s ICT security requirements.
- Network security: All services are isolated from the internet, which aligns with the principle of minimizing exposure (required by both ISO27001 and NIS2 for securing systems). Private endpoints and firewalls guard the data plane. Even Azure DevOps connectivity is handled via a secure agent. This reduces the attack surface area (a key consideration in NIS2, which focuses on preventing unauthorized access to networks and information systems). The use of Azure Firewall or similar for egress with allow-listing ensures even outbound traffic is controlled, helping meet compliance around data exfiltration prevention.
- Encryption and data protection: Communications between pipeline agent and Azure services (AKS, ACR, etc.) occur over private links which are encrypted in transit. At rest, resources like ACR and AKS secrets are encrypted by Azure (with platform-managed keys by default, or customer-managed keys if required for compliance). NIS2 also highlights the need for encryption for data at rest and in transit - Azure provides that by default for these services, and Private Link ensures in-transit encryption plus network-level security. If using Key Vault for secrets, you can even use customer-managed keys for Key Vault. All these can be documented as part of compliance evidence.
- Monitoring and incident response: The pipeline can integrate with Azure Monitor and Microsoft Defender for Cloud. For example, enabling Container Registry scanning in Defender will continuously scan images in ACR for vulnerabilities (addressing operational resilience by proactively catching issues). You could also schedule pipeline runs that perform security tests (like regular Terraform plan comparisons to detect drift, or running kubectl costraint checks). DORA requires a ICT resilience testing program at least yearly - with everything in code, you can more easily perform DR drills (e.g., tear down and recreate an environment from scratch to verify backups and IaC). The pipeline’s automated nature and infra-as-code make it feasible to spin up a staging environment identical to prod for testing recovery scenarios, which is a DORA objective. Additionally, any security logs from Azure AD (like PIM activations, failed login attempts) and from AKS (via Azure Monitor) can feed into a SIEM for continuous monitoring, satisfying ISO27001 and NIS2 requirements for detecting and reporting incidents.
- Compliance automation: Azure Policy can be used in conjunction with this setup to enforce rules (for instance, ensure no public IPs on resources, ensure diagnostics are enabled, etc.). Terraform can deploy Azure Policy definitions or initiatives that align with ISO/NIS2 controls, and these policies can deny or audit non-compliant configurations. This provides an extra gate - even if someone tried to introduce a non-compliant setting via Terraform, Azure Policy would flag it. For example, a policy can require that AKS has private cluster enabled and Authorized IP ranges empty (no public access) - which our Terraform should comply with. Such guardrails show defense in depth for compliance.
- Documentation and audit: All aspects of this pipeline and architecture can be documented as part of your ISMS (Information Security Management System) for ISO27001. The use of standard tools (Azure DevOps, Terraform, ArgoCD) provides clear points to show auditors: e.g., demonstrate how a code change flows to production with approvals and how identities are managed. The pipeline itself, being code, can be reviewed for compliance. Also, the Azure DevOps environment checks (approvals, etc.) and role definitions form part of the technical controls under ISO27001 Annex A. We maintain that only authorized roles can deploy to production, which is aligned with DORA’s requirement that appropriate controls are in place for software deployment in critical systems.
In essence, this setup is “compliance-ready”: it uses industry best practices that map to the requirements of standards and regulations. By using GitOps and IaC, we ensure a high level of integrity and traceability (reducing human error and unauthorized changes) . By using Azure AD with PIM and Private networking, we enforce strong security measures (least privilege, MFA, network segregation) . These are exactly the kinds of measures auditors look for in ISO27001 certification audits and regulators expect for NIS2/DORA compliance.
In conclusion, the proposed single-pipeline approach provides a robust, secure CI/CD workflow for multi-environment AKS deployments. It leverages Terraform for reproducible infrastructure, Docker/ACR for container management, and ArgoCD for safe and automated Kubernetes deployments via GitOps. The entire process is wrapped in Azure DevOps with gated promotions, running in a locked-down network using managed identities. This design not only follows DevOps best practices but also builds security and compliance into the pipeline from the start. By adopting these patterns, you can achieve faster deployments with confidence that dev, staging, and prod are consistent - all while meeting the stringent requirements of standards like ISO 27001 and regulations like DORA and NIS2 for security and resilience.