Azure AKS platform¶
This document presents a hardened, enterprise-grade Azure Kubernetes Service (AKS) platform designed for security, compliance, and operational resilience. Built for deployment in Azure Sweden Central, the platform supports both general workloads and critical financial services workloads subject to DORA, NIS2, and ISO 27001.
Purpose¶
To provide a secure, scalable, and auditable container platform that enables multi-team operations under strict regulatory controls, using Infrastructure-as-Code and GitOps principles.
Strategic benefits¶
- Zero Trust Network Architecture: Implements the Burton model with Restricted, Trusted, and Semi-Trusted zones to isolate workloads and contain breaches.
- Multi-Tenant by Design: Teams (standard and regulated) are segregated through dedicated node pools, namespaces, and role-based access.
- End-to-End Automation: All deployments-infra and applications-flow through Azure DevOps and Argo CD, ensuring full traceability, auditability, and rollback.
- Compliance Coverage:
- ISO 27001: Enforced access control, encryption, and change tracking.
- NIS2: Logging, incident response readiness, and identity governance.
- DORA: Resilience through auto-healing clusters, multi-AZ HA, and codified DR procedures.
- Operational Visibility: Centralized telemetry via Azure Monitor, Sentinel, and optional Datadog/Prometheus, supporting proactive detection and regulatory reporting.
Risk reduction¶
- No Public Endpoints: All APIs are private; workloads reach external systems only through firewalls.
- PIM/MFA Enforcement: Admin roles require approval and expire by default.
- Secret Management: Fully integrated with Azure Key Vault using Managed Identity, ensuring no hard-coded credentials.
This document¶
This document specifies an Azure Kubernetes Service (AKS) based platform in the Azure Sweden Central region. It is designed with GitOps principles, Infrastructure-as-Code (IaC), and stringent compliance requirements (ISO 27001, NIS2, DORA) in mind. The architecture follows a Burton network security model, segregating systems into Restricted, Trusted, and Semi-Trusted zones for layered defense, and emphasizes multi-tenancy by separating standard teams and DORA teams. All resources are managed via code (Terraform), and Azure DevOps is the sole CI/CD system feeding into a GitOps continuous deployment via Argo CD.
Key goals of this platform include
- Strict Security & Compliance: Adherence to ISO27001 controls and EU directives (NIS2, DORA) through strong access control, network isolation, encryption, and auditing. (For example, NIS2 mandates enhanced network security, incident handling, and access control1, while DORA requires resilient ICT systems.2)
- Maintainability & GitOps: All infrastructure and cluster configurations are defined in Git repos and continuously reconciled with the cluster (preventing config drift and ensuring auditable change management).
- Multi-Tenancy: A single platform hosting multiple teams (tenants) with isolation. “Standard” and “DORA” teams each have dedicated node pools and namespaces corresponding to trust zones, ensuring one tenant’s workloads cannot interfere with others.
- Infrastructure-as-Code: Terraform is used to provision and manage Azure resources (network, AKS, ACR, etc.), with example code snippets provided. Policy as code (Azure Policies, Argo CD config) enforces security standards by default.
Architecture overview¶
High-Level Architecture: The platform uses a hub-and-spoke virtual network topology with a central hub for shared services (firewall, gateways) and a spoke VNet for the AKS cluster. This implements the Burton model of segregated zones: the Hub VNet hosts the DMZ and external connectivity (Semi-Trusted zone) and security appliances, while the Spoke VNet hosts the AKS cluster and internal services (Trusted/Restricted zones). The design aligns with a zero-trust approach by strictly controlling ingress and egress at each boundary3.
![Figure 1: High-level network architecture. The hub VNet contains Azure Firewall (for egress filtering), a VPN/ExpressRoute gateway to on-prem (if needed), and Azure Bastion for secure admin access. The spoke VNet hosts the AKS cluster (segmented into multiple node pools for system, “Standard” and “DORA” zones). Azure Application Gateway with WAF in the spoke handles inbound traffic from the internet into AKS. Azure Key Vault and Azure SQL use Private Link endpoints into the spoke for secure access.]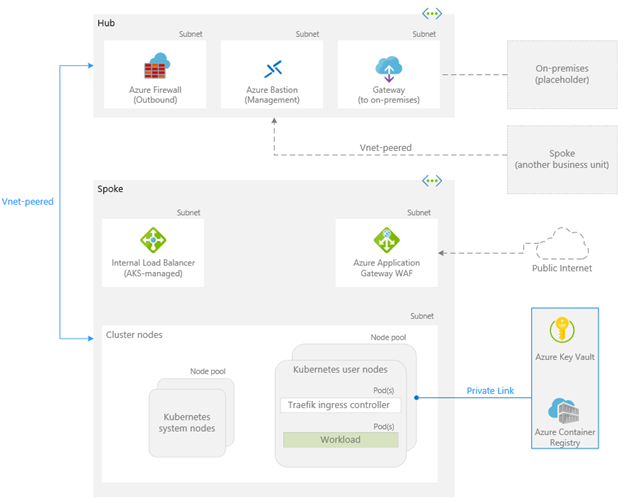
Important components illustrated above:
- Azure Firewall in Hub (Outbound): All outbound traffic from AKS is forced through the Azure Firewall, which acts as an egress point enforcing allow/deny rules. This forms a barrier between Trusted resources and the untrusted Internet, as well as providing monitoring of outbound flows.
- Azure Application Gateway with WAF in Spoke (Inbound): All public ingress to AKS (user web traffic, API calls) terminates at the Application Gateway (layer 7 load balancer). The integrated Web Application Firewall (WAF) filters attacks using OWASP Core Rule Set and custom rules before forwarding allowed traffic to the cluster’s services.
- AKS Cluster in Spoke: The cluster nodes are deployed into subnets that are peered with the hub. Network Security Groups (NSGs) at subnet level further restrict traffic (e.g. block any direct SSH or internet egress from nodes4). Inside the cluster, multiple node pools map to different trust zones (Restricted/Trusted/Semi-Trusted) and tenants (Standard vs DORA) - ensuring isolation at the node (VM) level as well as via Kubernetes constructs (namespaces, network policies).
- Private Endpoints: All Azure PaaS services (Container Registry, Key Vault, SQL Database) used by the platform have Private Endpoint NICs within the Spoke (or hub) VNet. This allows AKS and build agents to communicate with these services over the internal network, with no traffic exposed to public networks. DNS for these services is configured via Azure Private DNS Zones so that their standard names resolve to internal IPs.
Burton Network Security Model: Adopting Burton’s model, the platform defines security zones to isolate environments by risk level. A Semi-Trusted zone (DMZ) is the buffer between the untrusted internet and internal networks5, hosting resources like the WAF gateway and jump boxes. Behind this lies the Trusted zone, accessible only through controlled entry points and containing sensitive services (AKS, databases). The Restricted zone is an even more locked-down segment for highly sensitive or critical components (e.g. regulatory DORA workloads) with minimal external connectivity. By segmenting traffic and enforcing checks at each zone boundary, the blast radius of any incident is limited and least privilege network access is maintained. Each zone’s traffic flows and controls are documented (e.g. network flow diagrams showing ingress/egress and internal flows are maintained per compliance requirements6).
Compliance considerations:¶
- ISO 27001: The architecture implements controls for network security, access management, and system monitoring as required by ISO27001’s Annex A. For example, network segmentation and firewalls protect resources from unauthorized access (supporting control objectives for secure networks), and role-based access with just-in-time privileges supports access control policies. Encryption is used for data in transit and at rest across the platform.
- NIS2: The design’s emphasis on incident logging (Sentinel SIEM integration) and access control meets NIS2’s baseline measures (which call for improved network security, incident handling, and MFA-enabled access)78. Critical resources are isolated and continuously monitored, and incident response plans (outside the scope of this doc) are facilitated by centralized logging of security events.
- DORA: The Digital Operational Resilience Act mandates resilient and secure ICT for financial services. This architecture builds in high availability (multi-AZ deployment of AKS nodes and gateway), automated recovery via GitOps, and continuous monitoring - thereby minimizing the impact of ICT risks through resilient systems and controls . Regular resilience testing (chaos testing, failover drills) can be conducted thanks to the reproducible infrastructure and monitoring in place, supporting DORA’s testing requirements. Additionally, by using Azure’s cloud services, the platform leverages Azure’s compliance with DORA as a critical ICT third-party.
Network security and segmentation¶
Virtual network topology¶
The Hub VNet contains shared network services and entry/exit points:
- Azure Firewall Subnet: Houses the Azure Firewall instance which all egress from the spoke is routed through. The firewall has a static private IP which is used as the next-hop in user-defined routes for AKS subnets, forcing outbound traffic through it.
- Gateway Subnet: ExpressRoute Gateway enabling hybrid connectivity. If present, on-prem networks are connected to the hub, and routing can allow on-prem to reach the AKS spoke (for instance, for developers or legacy services access) through the firewall.
- Azure Bastion Subnet: Provides secure RDP/SSH access to any VMs (e.g. jumpboxes VMs if needed for troubleshooting) without exposing them via public IP.
The Spoke VNet is peered to the Hub and contains:
- AKS Node Subnets: Separate subnets for each node pool (or group of pools) aligned to a security zone. For example, one subnet for “Standard” node pools and another for “DORA” node pools, or even one per zone (Restricted/Trusted/etc.) for finer NSG control. Each subnet is associated with NSGs that limit allowed traffic (e.g., only allow necessary intra-VNet traffic, deny internet). Splitting node pools by subnet means we can apply subnet-level restrictions per pool9.
- Application Gateway Subnet: A dedicated subnet for the Azure Application Gateway (WAF) appliance. This subnet only needs to allow inbound from the internet (if App Gateway has a public IP) and outbound to the AKS node subnet (for backend traffic). NSGs here restrict source IPs if needed and ensure only the firewall or required sources can reach the gateway on management ports.
- Private Endpoint Subnet: A small address space for Private Link endpoints (for ACR, Key Vault, SQL, etc.). This subnet is isolated to only host these special NICs. NSG can restrict this to only allow connections from within VNet (which is by default for PEs).
Traffic between hub and spoke is via VNet Peering (with useRemoteGateways and allowGatewayTransit on the spoke if it should route internet traffic via the hub’s gateway/firewall). The hub’s Firewall can thus inspect traffic between spoke and external networks. Within the spoke, routing is configured so that:
- Egress from AKS subnets: A User-Defined Route (UDR) table on AKS subnets directs 0.0.0.0/0 to the Azure Firewall’s IP. Similarly, UDRs can direct on-prem IP ranges to the Gateway. This ensures no pod or node traffic goes directly out; everything hits the firewall first for policy enforcement. Azure Firewall then either forwards allowed traffic to its destination or drops it if not permitted. This addresses threats like data exfiltration or C2 callbacks by filtering unknown destinations 10.
- Ingress to AKS: Public ingress arrives at the Application Gateway (with WAF) which then sends it to cluster services (either via an AKS internal load balancer IP or directly to pod endpoints if using the AGIC controller). No direct public access to cluster nodes or services is allowed. For private ingress (e.g. from on-prem), traffic can come via VPN/ER Gateway to the firewall and then to an internal LB in AKS.
Network Policies in AKS: In addition to Azure-level segmentation, in-cluster Kubernetes NetworkPolicy resources enforce micro-segmentation between pods. The cluster is configured with a default deny-all posture: all namespaces (except essential system ones) get a default NetworkPolicy that denies any ingress/egress that isn’t explicitly allowed 11. This means even if two workloads share a node or VNet, they cannot communicate unless a policy whitelists the connection. All inter-service communications are locked down to least privilege. These policies are managed via GitOps (YAML in Git repos) so that any required exception (e.g., allowing a specific app namespace to call another app’s service on a certain port) is reviewed and committed to source control. By treating network policies as code, we maintain an audit trail for why a given flow was opened (useful for compliance sign-offs).
Burton Model Zone Implementation:¶
- Restricted Zone: In our context, this could correspond to internal-only critical workloads. Workloads designated “Restricted” run on dedicated node pools (with taints so only specific pods can schedule there) and perhaps in dedicated namespaces with extra hardened settings (e.g., cannot have internet egress at all, even via firewall, except to specific endpoints). The restricted node pool subnets can further be locked in NSGs to disallow any outbound except to known IPs (like a database tier). This zone might host things like core banking services (for DORA) or sensitive data processing that must not be exposed.
- Trusted Zone: This is the normal internal zone for general workloads that are trusted to run in the internal network but not as sensitive as Restricted. These run on their own node pools/namespaces and can have broader access (e.g., allowed egress to some external APIs via firewall rules). They still are not internet-facing directly; they rely on the semi trusted and share internal networks with other services.
- Semi-Trusted (DMZ) Zone: This zone contains frontend applications that receive traffic from the Application Gateway. These apps are internet-facing but not directly exposed to the internet. They’re treated as semi-trusted due to their exposure risk. Access from this zone into the Trusted zones (e.g., AKS backend APIs or databases) is tightly controlled - typically only allowed on specific ports to known services. No backend or internal workloads run here; it’s strictly for presentation and limited business logic.
- Internet Zone: This is where the Application Gateway with WAF policies resides. It terminates incoming traffic from the public internet and applies security controls before forwarding requests.
By mapping these zones to node pools and network layers, we satisfy segregation requirements (e.g., a breach of a web-facing component in the semi-trusted zone cannot directly laterally move to a database in restricted zone - it would hit multiple firewalls and need to bypass network policies). This layered approach is aligned with both the Burton model and modern zero-trust segmentation practices.
Network and Firewall: Below is an example of defining the VNet, subnets, and an Azure Firewall with rules in Terraform (simplified):
resource "azurerm_virtual_network" "hub" {
name = "prod-hub-vnet"
address_space = ["10.0.0.0/16"]
location = azurerm_resource_group.hub.location
resource_group_name = azurerm_resource_group.hub.name
}
resource "azurerm_subnet" "fw_subnet" {
name = "AzureFirewallSubnet"
resource_group_name = azurerm_resource_group.hub.name
virtual_network_name = azurerm_virtual_network.hub.name
address_prefixes = ["10.0.0.0/24"]
}
resource "azurerm_firewall" "network_fw" {
name = "hub-fw"
resource_group_name = azurerm_resource_group.hub.name
location = azurerm_resource_group.hub.location
sku_name = "AZFW_VNet"
subnet_id = azurerm_subnet.fw_subnet.id
}
resource "azurerm_firewall_policy" "fw_policy" {
name = "hub-fw-policy"
resource_group_name = azurerm_resource_group.hub.name
location = azurerm_resource_group.hub.location
threat_intel_mode = "Alert" # log threat intel hits, but don't block (could use Deny)
}
// Example: allow rule for Datadog logs and deny all else
resource "azurerm_firewall_policy_rule_collection_group" "datadog_allow" {
firewall_policy_id = azurerm_firewall_policy.fw_policy.id
name = "AllowDatadog"
priority = 100
application_rule_collection {
name = "ALLOW-DATADOG-OUT"
action = "Allow"
rules {
name = "allow_datadog_logs"
source_addresses = ["*"]
protocols = ["Https"]
destination_fqdns = ["http-intake.logs.datadoghq.eu"] # Datadog EU log endpoint
destination_ports = ["443"]
}
}
}
resource "azurerm_firewall" "network_fw" {
// ... (other properties as above)
firewall_policy_id = azurerm_firewall_policy.fw_policy.id
}
In the above snippet, we define a firewall and attach a policy. The policy’s rule collection allows traffic to Datadog’s log ingestion endpoint and, by omission, would block unknown destinations (the Azure Firewall denies anything not explicitly allowed). In practice, we’d add rules for other essential endpoints (Azure Container Registry FQDN, Microsoft update endpoints for node OS patches, etc.) - everything else is implicitly denied. This implements egress whitelisting.
We would similarly define the Spoke VNet and subnets for AKS and App Gateway, and use azurerm_route_table resources to route 0.0.0.0/0 to the firewall. All these definitions would be parameterized (CIDRs, region, etc.) and integrated into pipelines for repeatable deployment across environments (dev/test/prod). Proper tags (e.g., Environment=Prod, Owner=PlatformTeam, Compliance=DORA) are applied on all resources via Terraform to aid governance and cost tracking.
Azure application gateway with WAF¶
All external HTTP/S traffic enters via an Azure Application Gateway (WAF SKU) deployed in the spoke. The gateway is configured with:
- WAF Policy: A policy using the latest OWASP Core Rule Set for general threat protection (SQL injection, XSS, etc.) and any custom rules needed (for example, blocking specific IP ranges or geographies not relevant to our users, rate-limiting abusive clients, or enforcing application-specific headers). The WAF is run in Prevention mode so that malicious requests are blocked (not just logged). By using Azure’s managed WAF, we offload a lot of threat detection to a continually updated rule set12. Custom rules can also implement virtual patching for app vulnerabilities in an emergency.
- Listeners and Routing: The App Gateway listens on HTTPS (TLS termination can occur here, using a certificate stored in Azure Key Vault). It has listener rules for each public application endpoint (e.g. different domain names or paths for different services). The Azure Application Gateway Ingress Controller (AGIC) is deployed in AKS to automate the configuration: whenever a team deploys a new Ingress resource in Kubernetes (via Argo CD), AGIC will update the App Gateway’s backend pools and rules to route traffic to the appropriate service. This provides a seamless GitOps-driven ingress: developers declare ingress in their app manifests, and the platform’s gateway picks it up.
- Backend Pools: The gateway’s backend is the AKS cluster. AGIC can register either individual pod IPs or the cluster’s internal load balancer IP as targets. In our case, we could deploy an internal L7 ingress (like Istio’s ingress gateway or NGINX) for each trust zone and have App Gateway feed into those, or we can have App Gateway directly target pods. The simplest pattern is to allow App Gateway to directly reach pod IPs in the node subnet (the AKS subnet NSG will be configured to allow traffic from the App Gateway’s subnet). This eliminates the need for another hop and simplifies encryption (we can choose to do end-to-end TLS by having pods themselves do TLS or do TLS termination at the gateway).
- Private vs Public: The Application Gateway can have a public IP for external access and also a private IP. If certain apps are internal only (accessible via on-prem), we could use an internal-only gateway or split listener configuration. For strict environments, the gateway might only have a private IP (forcing users to VPN in). In our scenario, standard teams might have internet-facing apps, whereas DORA teams (financial apps) might be internal or behind extra VPN layers depending on risk - the gateway design accommodates both by simply not assigning a public IP for certain listeners.
Terraform example¶
resource "azurerm_application_gateway" "ingress_waf" {
name = "prod-appgw-waf"
location = azurerm_resource_group.spoke.location
resource_group_name = azurerm_resource_group.spoke.name
sku {
name = "WAF_v2"
tier = "WAF_v2"
capacity = 2 # two instances across AZs
}
zones = ["1", "2", "3"] # zone-redundant gateway
gateway_ip_configuration {
name = "gw-ipconfig"
subnet_id = azurerm_subnet.appgw_subnet.id
}
frontend_ip_configuration {
name = "fw-ip-public"
public_ip_address_id = azurerm_public_ip.appgw_public.id
}
frontend_ip_configuration {
name = "fw-ip-private"
subnet_id = azurerm_subnet.appgw_subnet.id
private_ip_address = "10.0.2.10"
private_ip_address_allocation = "Static"
}
frontend_port { name = "port-443" port = 443 }
ssl_certificate {
name = "tls-cert"
key_vault_secret_id = azurerm_key_vault_certificate.app_cert.id # certificate stored in Key Vault
}
http_listener {
name = "https-listener"
frontend_ip_configuration_name = "fw-ip-public"
frontend_port_name = "port-443"
protocol = "Https"
ssl_certificate_name = "tls-cert"
}
backend_address_pool {
name = "aks-pool"
// addresses will be auto-added by AGIC, or we could statically point to ILB IP
}
backend_http_settings {
name = "aks-backend-setting"
cookie_based_affinity = "Disabled"
port = 80
protocol = "Http"
request_timeout = 30
// If end-to-end TLS, we'd use protocol = "Https" and upload the backend cert for the pod or use Trusted Root
}
request_routing_rule {
name = "rule1"
rule_type = "Basic"
http_listener_name = "https-listener"
backend_address_pool_name = "aks-pool"
backend_http_settings_name = "aks-backend-setting"
}
// Associate WAF policy
firewall_policy_id = azurerm_web_application_firewall_policy.waf_policy.id
}
resource "azurerm_web_application_firewall_policy" "waf_policy" {
name = "prod-waf-policy"
resource_group_name = azurerm_resource_group.spoke.name
location = azurerm_resource_group.spoke.location
policy_settings {
enabled = true
mode = "Prevention"
request_body_check = true
}
managed_rules {
managed_rule_set {
type = "OWASP"
version = "3.2" # latest OWASP Core Rule Set version
}
}
custom_rule {
name = "BlockBadBots"
priority = 1
action = "Block"
match_conditions {
match_variables { variable_name = "RequestHeaders" selector = "User-Agent" }
operator = "Contains"
match_values = ["BadBot"]
negation_condition = false
transforms = []
}
}
}
In this snippet, we define an App Gateway listening on 443 with a WAF policy. The WAF policy enables OWASP rules and shows a sample custom rule blocking a fake “BadBot” user-agent. The gateway uses a certificate from Key Vault (Azure provides seamless integration for App Gateway to fetch certificates from Key Vault given proper access policy), which illustrates secure key management - ops can update the TLS cert in Key Vault and the gateway will pick it up. The backend pool and settings are placeholders here; in reality, AGIC would dynamically configure them based on Kubernetes Ingress resources.
Note: The real configuration of App Gateway in a GitOps context means minimal static config in Terraform - instead, deploy AGIC (Argo CD will deploy that as part of cluster add-ons) and let Kubernetes manifests drive listeners and routing. We will use Terraform to set up the WAF policy and attach it, as well as to create the gateway itself with basic listener ready to be managed by AGIC.
Inbound Flow Summary: A client hits the DNS of an app (which maps to App Gateway’s public IP). The WAF (App Gateway) examines the request against OWASP rules and our custom rules. If it’s malicious (e.g., SQL injection in URL), WAF blocks it (HTTP 403). If allowed, the request is forwarded to the configured backend - which is an AKS service (the gateway might forward to an Istio ingressgateway service in AKS, or directly to the app pods. Istio gateway not included in this solution). Mutual TLS within the cluster (via Istio) and network policies then control what the request can reach, as described later. This multi-layer check (WAF then in-cluster policy) implements defense in depth. For example, a certain exploit might slip past WAF but then be contained by an Istio authorization policy at the service level. Conversely, an internal attack vector wouldn’t go through WAF but would still face network policies.
Azure firewall¶
Azure Firewall is centrally positioned to handle:
- Outbound to Internet: As discussed, only approved endpoints are allowed. For instance, container images come from our Azure Container Registry (private link, so not via firewall), but some base images might be pulled from Microsoft’s container registry (mcr.microsoft.com) - we would allow that domain. If applications call external APIs (e.g., a third-party service), each must be reviewed and added to firewall rules. This not only prevents data exfiltration but also provides a log of all egress attempts which can be sent to Sentinel for anomaly detection.
- Outbound to Azure Services: Even Azure services we use are locked down. Where possible, we use private link (so that traffic never leaves VNet). In cases where private link isn’t available, we use firewall rules to restrict access. For example, if an app needs to access an Azure Service Bus namespace (which might not support private link), we restrict egress to that specific FQDN.
- On-Prem Connectivity: If the AKS apps need to call on-prem services or databases, traffic goes out via the firewall to the VPN/ER gateway. The firewall can be configured with network rules to allow on-prem IP ranges. If we want to inspect on-prem traffic too (for intrusion), we could even route it through firewall (though often trusted internal traffic may bypass it). The hub can be set up such that on-prem to cloud traffic passes through firewall as well - this ensures even lateral flows are inspected.
- East-West (VNet to VNet): In case there are multiple spokes (e.g., another spoke VNet for a legacy system or another AKS), traffic between spokes could be forced through the hub firewall by using user-defined routes. By default VNet Peering allows direct VM-to-VM traffic, but we might apply firewall if needed for compliance.
The firewall is configured with Azure Firewall Policy (a global resource that can be reused if we had multiple firewalls). Using Firewall Policy as code (Terraform supports it) allows us to version control the firewall rules. We also enable Threat Intelligence on the firewall in alert mode (which logs if any known bad IP or domain is contacted, and we could set it to block high-risk ones automatically). This is not set in version one.
Logging and Monitoring: Both Application Gateway and Azure Firewall send diagnostic logs to Log Analytics and Sentinel. WAF logs will show any attacks/blocks (helpful to tune rules or investigate incidents), and firewall logs will show attempted connections, hits/misses on rules. These logs are crucial for meeting NIS2 and DORA reporting obligations - e.g., NIS2’s requirement for prompt incident reporting  is aided by having these telemetry feeds to quickly identify malicious activity. The platform team can set up Sentinel analytics rules to alert on suspicious patterns (e.g., multiple firewall denies to an IP might indicate a compromised pod trying to call out).
Common Pitfalls & Best Practices¶
- DNS for Private Endpoints: Each private endpoint in Azure has a weird FQDN (like yourvault.vaultcore.azure.net maps to guid.vaultcore.vnet.azure.cloudapp.net). We must create proper Azure Private DNS zones (e.g., privatelink.vaultcore.azure.net) and link them to the VNet, otherwise the services won’t resolve for our apps. A common pitfall is forgetting DNS integration - resulting in timeouts even though the private link is set. Our Terraform will include creating those DNS zones and appropriate records when provisioning PEs.
- IP Address Planning: The VNet and subnet sizes should be planned to accommodate future growth (more node pools or more endpoints). AKS in particular, if using Kubenet (not in our case, we use Azure CNI), requires planning of IPs for pods. We choose Azure CNI for simplicity (pods get real IPs in the VNet), but that means each node consumes IPs. Ensure subnets (like the node pool subnets) are sufficiently large (e.g., /24 or larger) to avoid IP exhaustion when scaling.
- Firewall Rule Specificity: Use FQDN rules whenever possible (Azure Firewall can filter by DNS names for HTTP/S). This simplifies rules vs chasing ephemeral IPs. But be aware of wildcard allowances - e.g., allowing *.windowsupdate.microsoft.com for OS updates. Monitor firewall logs for denied traffic to catch any needed endpoints that were missed.
- Performance: App Gateway WAF and Azure Firewall do add some latency and throughput limits. Right-size the SKU (e.g., Firewall Standard vs Premium, WAF capacity units) based on load. For high throughput scenarios (many GB/s), plan scaling or alternatives (like Azure Front Door for global WAF + caching, though here we stick to regional gateway for simplicity and compliance location). If needed network policy can allow traffic container to container if set in configuration.
AKS cluster design and hardening¶
The AKS cluster is the core of the platform. It’s configured from the ground up for multi-tenant security, GitOps management, and policy enforcement:
Cluster configuration¶
- Private API Server: The AKS control plane endpoint is not exposed to the internet. It’s accessible only within the Azure network (by default, the cluster’s API IP is in a Microsoft-managed VNet, but we enable Private Cluster which associates a private endpoint in our VNet). This means all kubectl or API access must occur from within the network (either from a jumpbox/Bastion or from an Azure service with network access, like Azure DevOps agent or Argo CD within the cluster). This greatly reduces the attack surface - no public API means attackers can’t hit the Kubernetes API from the internet at all.
- Azure AD Integration: The cluster is integrated with Azure AD for authentication. We enable AKS-managed Azure AD which ensures no local Kubernetes admin users exist, and Azure AD accounts must be used to get tokens. This ties into our RBAC model (described in the Identity section). Admin group IDs are provided at cluster creation so that we have an emergency backdoor (via PIM-controlled AAD group membership) to administer the cluster. Azure AD integration also allows us to use AAD groups in Kubernetes RBAC bindings seamlessly.
- Azure RBAC for Kubernetes: (Optional) AKS has an option to use Azure RBAC to manage Kubernetes RBAC (where Azure role assignments like “Azure Kubernetes Service RBAC Reader” on a namespace scope translate to Kubernetes permissions). We can either use that or the standard Kubernetes RBAC with AAD identities. We will mostly rely on native Kubernetes RBAC for fine-grained control, but one could layer Azure RBAC for high-level separation (for example, only allow certain AAD apps to deploy to certain namespaces via Azure’s IAM).
- Network Plugin & Policies: We choose Azure CNI as the network plugin, which means pods get first-class IPs in the VNet and can directly use private endpoints. This simplifies connectivity (no need for additional routing for pod IPs). For network policies, we enable Calico. Calico supports the standard NetworkPolicy API and is compatible with Azure CNI. Azure offers its own NP plugin, but Calico is chosen for familiarity and potentially advanced features (Calico can also do host-based policies if needed). With Calico, we implement the default deny as mentioned.
-
Node Pools: We utilize multiple node pools to separate workloads:
-
System Node Pool: A small pool for AKS system pods (like kube-system components, Calico, CoreDNS, metrics agents). This runs on tainted nodes (node.kubernetes.io/role: agent but tainted as CriticalAddonsOnly or similar) so that application pods don’t land on them. This pool is in its own subnet with an NSG that perhaps allows required Azure management traffic (AKS health probes, etc.). We keep this pool minimal (e.g., 3 nodes) and on a smaller VM size, as it only runs infra components.
- User Node Pools (Standard Teams): Three pools corresponding to Restricted-Standard, Trusted-Standard, SemiTrusted-Standard. For instance, pool-standard-restricted, pool-standard-trusted, pool-standard-semi. These could be on different VM sizes if needed (maybe Restricted gets larger VMs for heavier workloads?). Each pool has a taint, e.g., zone=restricted:NoSchedule and a label like zone=restricted so that we can target them. Standard team workloads will be scheduled on these pools according to their classification. For example, a front-end web pod might run on semi-trusted pool (if we consider it needs to talk out to internet), whereas a backend service with important data might run on trusted. (We define how we decide which goes where as part of deployment guidelines for teams.)
- User Node Pools (DORA Teams): Similarly, separate pools for Restricted-DORA, Trusted-DORA, SemiTrusted-DORA. This ensures that DORA-critical workloads (which may be subject to additional controls or higher sensitivity) do not share nodes with standard workloads. Even if two sets of apps are both “trusted zone”, if one is DORA and one is not, they reside on different pools. This aids compliance isolation - e.g., for DORA we might enforce stricter patching or monitoring on those nodes, and in an incident we could even shut down all DORA pools without affecting standard pools.
- Each node pool can scale independently. We might set higher auto-scaling limits for some and keep Restricted pools more static (since those host stateful critical things perhaps).
- Node taints coupled with Kubernetes tolerations in pods ensure that, for example, a standard team’s pod cannot be scheduled to a DORA node pool (because it wouldn’t have the proper toleration for the DORA taint). This separation is an important multi-tenancy control. Even if a team had misconfigured something, Kubernetes wouldn’t co-locate their pods on a different tenant’s nodes.
- Pod Security Policies/Standards: We enforce the Kubernetes Pod Security Standards at the Restricted level for all application namespaces. In practice, we use either the built-in Pod Security Admission in AKS or OPA Gatekeeper with PSP-equivalent constraints. This ensures, for example: no privileged containers, no host network, no host volume mounts, no running as root (or at least disallow root for most cases), and no privilege escalation. These settings align with compliance best practices (CIS Benchmark for Kubernetes, etc.). We treat any violation as a deployment error - Argo CD would be unable to apply a manifest that doesn’t meet these criteria. Additionally, images must run as a non-root user wherever possible (developers are guided to design images accordingly).
- Restricted Egress for Pods: At the Kubernetes level, we also implement restrictions on egress. By default, pods can’t reach external endpoints except what’s allowed - partly achieved by Azure Firewall, but also by NetworkPolicy. For example, we might add an egress policy in each namespace to only allow traffic to known CIDR ranges (like the IP of our Azure Firewall - forcing all egress to go there, although by routing it happens anyway, NP could further limit direct traffic to say other VNets). If a pod tries to bypass firewall by connecting to some IP in the VNet (maybe some malicious container with a backdoor), we have an NSG and NP in place. Defense in depth principle means multiple layers prevent an issue if one layer misconfigures.
-
Istio Service Mesh: We deploy Istio on the cluster (via GitOps) to leverage its security features:
-
Mutual TLS (mTLS): Istio auto-injects sidecar proxies (Envoy) into pods. All traffic between services within the mesh is encrypted and authenticated via mTLS. This means even if someone manages to sniff the pod network (which is already hard since it’s inside Azure VNet), they’d see encrypted data. It also means if network policy accidentally allowed more than it should, the receiving service still ensures the caller has a valid Istio identity. We set Istio PeerAuthentication to “STRICT” so that only mTLS traffic is accepted by services (no plain-text).
- Authorization Policies: We can define Istio AuthorizationPolicies to control which service account (identity) can access which service. For instance, enforce that the front-end service can call the backend service, but nothing else can. This is like an application-level firewall inside the cluster. It complements NetworkPolicy (which is more IP/port based), by adding application identity-based rules. These policies are defined as YAML and managed in Git as well for audibility.
- Ingress/Egress Gateway: Istio’s ingress gateway could be used as an internal ingress for certain scenarios (though primarily we rely on App Gateway). Istio egress gateway could be configured for calls to external services to funnel them for monitoring, but since we have Azure Firewall doing that, we may not need Istio egress unless we want mTLS from mesh out to an external service with a known cert. At minimum, Istio gives us encryption and authN/Z within cluster, which is a big security win.
- We ensure Istio control plane (istiod) and gateways run only in the appropriate node pools (probably the trusted zone pool, since they are internal control components). We label and taint nodes such that, for example, istiod might run on the “Trusted-Standard” pool with toleration for an infra=true taint. This avoids mixing control plane pods with user workloads.
Terraform Example¶
resource "azurerm_kubernetes_cluster" "aks" {
name = "prod-cluster"
location = azurerm_resource_group.spoke.location
resource_group_name = azurerm_resource_group.spoke.name
kubernetes_version = "1.27.3" # example version, ideally fetch latest stable
dns_prefix = "prodaks"
private_cluster_enabled = true
private_dns_zone_id = azurerm_private_dns_zone.aks.id # if using custom Private DNS for API
api_server_authorized_ip_ranges = [] # leave empty to force private-only access
identity { type = "SystemAssigned" }
oidc_issuer_enabled = true # Enable OIDC for federated identity (Workload Identity)
azure_active_directory {
managed = true
admin_group_object_ids = [var.aad_group_aks_admin_id] # PIM-controlled Azure AD group for cluster admins
}
role_based_access_control { enabled = true }
network_profile {
network_plugin = "azure"
network_policy = "calico"
service_cidr = "10.100.0.0/16"
dns_service_ip = "10.100.0.10"
docker_bridge_cidr = "172.17.0.1/16"
outbound_type = "userDefinedRouting" # ensures AKS will not create its own outbound LB
}
default_node_pool {
name = "sys"
vm_size = "Standard_D4s_v5"
node_count = 3
type = "VirtualMachineScaleSets"
node_taints = ["CriticalAddonsOnly=true:NoSchedule"]
tags = {
"Zone" = "system"
"Owner" = "PlatformTeam"
}
}
// Add-on profiles
addon_profile {
oms_agent { enabled = false } // disable default Container Insights agent (we'll deploy custom DaemonSets)
azure_policy { enabled = true } // enable Azure Policy for AKS (Gatekeeper)
}
}
// User Node Pools
resource "azurerm_kubernetes_cluster_node_pool" "standard_restricted" {
cluster_name = azurerm_kubernetes_cluster.aks.name
name = "std-r"
vm_size = "Standard_D8s_v5"
node_count = 2
node_labels = { "tenant" = "standard", "zone" = "restricted" }
node_taints = ["tenant=standard:NoSchedule", "zone=restricted:NoSchedule"]
vnet_subnet_id = azurerm_subnet.aks_nodes.id // could also use a dedicated subnet for restricted
tags = { "Zone" = "Restricted", "Tenant" = "Standard" }
}
resource "azurerm_kubernetes_cluster_node_pool" "standard_trusted" {
cluster_name = azurerm_kubernetes_cluster.aks.name
name = "std-t"
vm_size = "Standard_D4s_v5"
node_count = 3
node_labels = { "tenant" = "standard", "zone" = "trusted" }
node_taints = ["tenant=standard:NoSchedule", "zone=trusted:NoSchedule"]
vnet_subnet_id = azurerm_subnet.aks_nodes.id
tags = { "Zone" = "Trusted", "Tenant" = "Standard" }
}
resource "azurerm_kubernetes_cluster_node_pool" "standard_semi" {
cluster_name = azurerm_kubernetes_cluster.aks.name
name = "std-s"
vm_size = "Standard_D4s_v5"
node_count = 3
node_labels = { "tenant" = "standard", "zone" = "semi" }
node_taints = ["tenant=standard:NoSchedule", "zone=semi:NoSchedule"]
vnet_subnet_id = azurerm_subnet.aks_nodes.id
tags = { "Zone" = "SemiTrusted", "Tenant" = "Standard" }
}
// Repeat similarly for DORA restricted/trusted/semi node pools:
resource "azurerm_kubernetes_cluster_node_pool" "dora_restricted" {
cluster_name = azurerm_kubernetes_cluster.aks.name
name = "dora-r"
vm_size = "Standard_D8s_v5"
node_count = 2
node_labels = { "tenant" = "dora", "zone" = "restricted" }
node_taints = ["tenant=dora:NoSchedule", "zone=restricted:NoSchedule"]
tags = { "Zone" = "Restricted", "Tenant" = "DORA" }
// possibly use a separate subnet for DORA pools for stronger isolation
}
In the above, notice we label/taint nodes with both tenant and zone. Pods will have to carry matching tolerations. For example, a pod from standard team in restricted zone would have tolerations for tenant=standard:NoSchedule and zone=restricted:NoSchedule. Argo CD can inject these tolerations via Kustomize patches or they can be in the team’s deployment manifests (the platform team will likely provide base Helm charts or templates that already include the proper tolerations based on an “environment” value). By doing this, scheduling is strictly controlled. Even if a user had high Kubernetes rights, they’d have to deliberately add tolerations to move pods to another tenant’s nodes - which we don’t permit via RBAC (and Azure Policy can even prevent certain labels/tolerations usage if needed).
Azure Policy Add-on: We enabled azure_policy. Azure provides a set of policy definitions for AKS via the add-on (backed by Gatekeeper). Examples of enforced policies: no privileged containers, no SSH port in containers, require approved base images, etc. We will enable a built-in initiative like “Kubernetes cluster pods should only use allowed container images” where we specify our ACR as allowed registry. This means if someone tries to run an image from Docker Hub, it will be blocked at admission13. Also, we use the “baseline” policy set that checks for dangerous settings (like hostPath mounts, privilege escalation). These policies help catch misconfigurations or unsafe deployments early - Argo CD will report sync errors if a manifest violates a policy (since admission webhook will reject it), prompting developers to fix their configurations.
Argo CD Deployment: Argo CD itself lives in the cluster (in a namespace e.g. “argocd”). We deploy Argo CD via Terraform Helm provider or via a bootstrapping manifest. Argo CD is configured with internal access (no public service). We will expose the Argo CD UI on an internal DNS (or simply have teams use kubectl port-forward when needed). Alternatively, we can set up an internal Ingress for Argo CD on the App Gateway (with host like argocd.platform.internal) accessible via VPN. The Argo CD uses Azure AD OIDC for login, tied to our AAD groups (this gives us SSO and the same MFA/PIM controls for accessing Argo as any Azure resource).
Logging and monitoring agents on AKS¶
- The Datadog agent (if using Datadog for app logs/APM) runs on all nodes. It is configured only to send application logs/metrics (we may disable host network metrics since we have Prometheus for that, to avoid overlap). Datadog agent will use an API key which we store in Key Vault and feed via a Kubernetes Secret (populated through pipeline or external secrets). We ensure that egress to Datadog (specific domains on port 443) is allowed in Azure Firewall (as shown in the rule earlier).
- Prometheus Node Exporter / Kube State Metrics: If we run our own Prometheus, we’ll deploy node-exporter on each node and kube-state-metrics to feed cluster metrics (Pod count, etc.). Prometheus will scrape these and any pod metrics. We might run Prometheus itself either in the cluster (with persistent volume) or use Azure Managed Prometheus (currently in preview in Azure Monitor) to avoid managing it. For now, assume we run it in the cluster for full control. We also deploy Grafana (maybe an Azure Managed Grafana instance to integrate with Azure AD SSO, or simply a container in the cluster). Grafana will have data sources for Prometheus (for system metrics) and possibly for Log Analytics or Azure Monitor to visualize logs/metrics from Azure. If the organization has a separate Grafana, we could feed Prom data there.
- Azure Monitor Agent (AMA) for Linux: Instead of the older OMS agent, we could use the Azure Monitor Container Insights’ new version which is the Azure Monitor Agent that writes to Log Analytics. This can collect node syslogs, kubelet logs, etc. However, because we have many tools, we might choose to selectively use it. We do want audit logs of Kubernetes (if enabled) - AKS can send audit logs to Log Analytics/Sentinel directly from the control plane. We enable Kubernetes audit logs in AKS diagnostics (records every API call in cluster) and send those to Sentinel. That covers a lot of security monitoring (e.g., alerts if someone tries to escalate privileges in cluster).
GitOps workflow with ArgoCD and Azure DevOps¶
One of the central tenets of this platform is that all changes (infrastructure and application deployments) go through Git repositories and automated pipelines - aligning with GitOps best practices. Developers and operators do not directly manipulate cloud or cluster resources via CLI or portal; they propose changes in code and let pipelines/Argo apply them. This provides traceability (who changed what, when) and the ability to rollback if needed (since previous states are in Git).
![Figure 2: CI/CD and GitOps deployment workflow. In this example workflow (inspired by scenario 4 from Azure architecture  ), developers commit code to a repository. A CI pipeline (here showing GitHub Actions, but in our case Azure DevOps) builds and pushes a container image to ACR (step 3). The pipeline then updates a Kubernetes manifest (or Helm values) with the new image tag and commits that to a GitOps config repo (step 4). Argo CD notices the config change (step 5) and syncs the new version to AKS (step 6). This flow ensures the cluster state always matches the Git declarative config.]
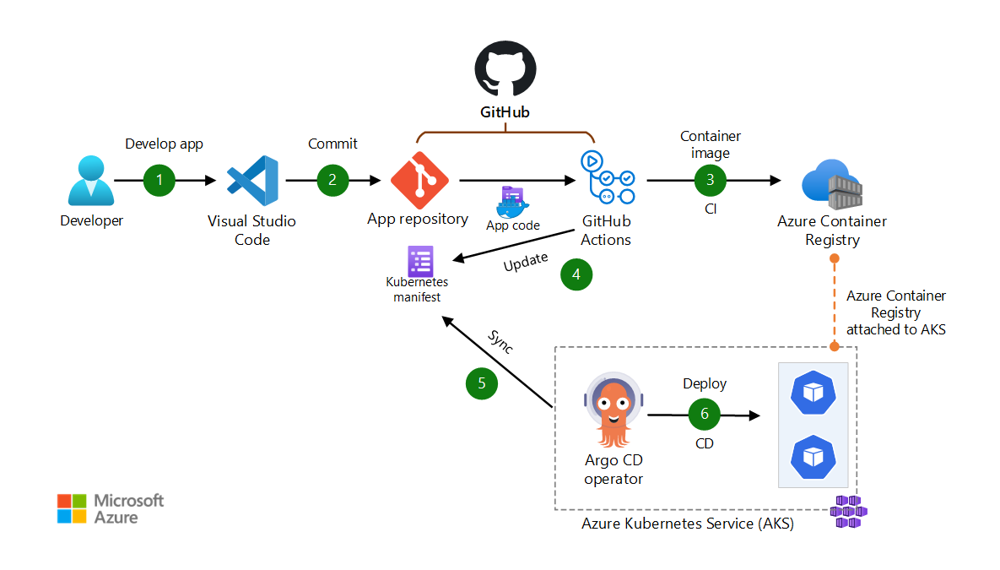
In our implementation with Azure DevOps:
- Repositories: We likely have at least two types of repos:
- App Source Repos (for each microservice or project) containing application code (which on push triggers CI build).
- Environment GitOps Repos (one per environment like dev, staging, prod - or one per team’s deployments) containing Kubernetes manifest YAMLs or Helm chart references that describe what should run in the cluster. These are the repos Argo CD monitors. They might be Azure DevOps Git repos (or could be on GitHub/other Git if Argo has access, but for simplicity and one system, we use Azure DevOps repos).
- CI Pipeline (Build): Azure DevOps Pipelines (YAML pipeline defined in the app repo) will build the Docker image, run tests, then push the image to Azure Container Registry (ACR). We ensure the pipeline uses a managed agent (Azure DevOps provides hosted agents or we can host our own). Given compliance, we may use self-hosted agents in our Azure subscription for build - possibly a VM scale set in the hub VNet, which can pull code and build images internally (ensuring no code goes to a public agent). These agents are locked down with no public IP and can reach ACR and our Git only. After push, the pipeline triggers a deployment step. Rather than directly kubectl applying, it will update the desired state in Git. For example, if using a simple approach, the pipeline could update the image tag in a Kubernetes Deployment YAML in the environment repo (via a PR or direct commit if automation user). We prefer a PR for audit - the platform might auto-approve it if everything is fine, or a release manager can review it.
- CD Pipeline (Argo CD): Argo CD is continuously watching the environment Git repo (which is specified in its Application definitions). As soon as the new commit (with new image tag) is merged, Argo sees the repo revision change. It pulls the updated manifests and applies them to AKS. If all policies are satisfied (no policy violations) and the pods come up healthy, Argo will report Sync OK. If something goes wrong (image crash looping, etc.), Argo can alert. We also set Argo CD’s sync policy to Automated with Self-Heal for most apps - this means it not only applies changes automatically, but if someone manually changed a resource (say a hotfix via kubectl), Argo will revert it to the last Git version (ensuring drift is reconciled). This satisfies the principle that Git is the single source of truth for cluster state. According to Microsoft’s guidance, this pull-based deployment approach is more secure because build agents don’t need direct access to the cluster API14. DevOps pipelines push to Git, and Argo (with appropriate minimal RBAC in the cluster) pulls from Git to deploy - developers and CI systems do not get broad Kubernetes credentials, reducing risk15.
- Argo CD Configuration: We set up Argo CD Projects to separate team scopes. For example, a “standard-team-project” and “dora-team-project” in Argo, each with permissions to certain namespaces. Argo CD itself can integrate with Azure AD for user SSO, so developers can view the Argo UI but only see their apps. We utilize Argo’s RBAC such that team A can’t accidentally sync or modify team B’s application. Argo is running with a Kubernetes ServiceAccount that has just enough permissions to create/update resources in the target namespaces (bound via RoleBindings). It does not run with full cluster-admin (to limit blast radius). For safety, Argo’s auto-sync can have safeguards like not pruning certain whitelisted resources (to avoid deleting core components).
- GitOps for Infrastructure: The infrastructure (VNet, AKS, etc.) is managed by Terraform via Azure DevOps as well, but not by Argo CD (Argo is for in-cluster K8s resources). We keep Terraform state in Azure storage and run terraform plan/apply in pipelines when infra changes are needed. Those changes are less frequent and go through a code review process. We treat Terraform code as another set of repos and possibly have separate pipelines per layer (e.g., network, security, AKS cluster, baseline services). This ensures even Azure resource changes are tracked (which is important for ISO27001’s change management control).
Build Agents: As noted, using self-hosted build agents might be necessary for compliance. We could have a pool of build VMs within a secure subnet. These VMs can have managed identities to pull from repos and push to ACR. We ensure they have no open ports (build runs are triggered by the Azure DevOps service through an agent polling mechanism). After each build, containers and other artifacts on the agent are cleaned (Azure DevOps agents do this by default to avoid cross-contamination between runs). If using Microsoft-hosted agents, we ensure no sensitive data is output during builds and rely on Microsoft’s compliance (which is generally high and even permissible under many regulations). Some orgs prefer self-hosted to ensure data residency (e.g., guarantee builds happen in Sweden datacenters). It’s a decision for the compliance officer - our platform supports both by simply pointing pipelines to the desired agent pool.
Argo CD Installation example¶
resource "helm_release" "argo_cd" {
name = "argo-cd"
repository = "https://argoproj.github.io/argo-helm"
chart = "argo-cd"
namespace = "argocd"
create_namespace = true
values = [
file("${path.module}/argocd-values.yaml")
]
}
Where argocd-values.yaml might set things like server.service.type: ClusterIP (no LoadBalancer), OIDC config for Azure AD (client ID, etc.), and resource limits. Post installation, we bootstrap the initial applications. For instance, we commit an Application manifest for Argo CD to deploy itself (App of Apps pattern). Alternatively, we use Argo CD’s auto-detect of a folder of apps.
Sample Argo CD Application Manifest:
# Argo CD Application that deploys team1's app
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: team1-prod-app
namespace: argocd
spec:
project: standard-team-project
source:
repoURL: https://dev.azure.com/OurOrg/Configs/_git/team1-prod-config
targetRevision: main
path: k8s/manifests
destination:
server: https://kubernetes.default.svc # the AKS cluster
namespace: team1-prod
syncPolicy:
automated:
prune: true
selfHeal: true
This tells Argo CD to continuously deploy the manifests from the team1-prod-config repo into the team1-prod namespace. We would have one such Application per deployed app or microservice (or one per team environment encompassing all their apps, depending on repo structure). Argo CD itself can be configured via Terraform by creating these Application resources as Kubernetes manifests (with the Terraform Kubernetes provider or Helm chart values that include some apps).
GitOps Best Practices:
- We keep configuration separate from application code (as recommended by GitOps principles16). Developers don’t mix Kubernetes YAML in their app repo; instead, they treat the config repo as a representation of the environment. This also allows operations team to manage some config (like network policies or base namespaces) in the environment repo, while developers manage app-specific deployments.
- We implement branch protections on these repos: e.g., changes to prod folder require pull request review by a lead and maybe even an approver from ops (especially for DORA-covered apps). This ensures no single developer can push straight to production config - aligning with change management controls (ISO27001) and four-eyes principle often required in financial IT. Azure DevOps Repo policies will be configured for this.
- Secrets in Git: We do not put raw secrets in Git. Instead, we use placeholder references. For instance, a deployment manifest might reference a Kubernetes Secret that is expected to exist (populated by External Secrets from Key Vault). Our Git can contain a template or a Secret manifest encrypted with Mozilla SOPS or Azure Key Vault integration. A good pattern is using External Secrets Operator: in Git, we place an ExternalSecret resource that says “fetch secret X from Key Vault into a Kubernetes Secret”. Argo deploys that, and the operator pulls the actual secret at runtime. This way the actual secret value is never in Git. This approach requires the AKS workload identity to have permission to read that Key Vault secret. We will set that up in the Identity section.
Rollback and DR: If a deployment causes issues, Argo CD can roll back to a previous Git commit simply by selecting that revision and syncing. This is far more reliable than trying to manually fix a broken deployment. In case of disaster (region failure), since everything is in code, we can recreate the entire infrastructure and cluster in a secondary region (assuming we have a plan for data like database replication). For DORA, having such Infrastructure-as-Code and GitOps means we meet the requirement of being able to recover and reconstitute services in a consistent manner, as well as test this process (we could simulate a region outage by pointing Argo to deploy to a DR cluster, etc.).
Multi-Tenancy Considerations: We ensure that teams are given appropriate scopes:
- Team namespaces are created ahead of time (via GitOps as well - a “platform” config that Argo applies which makes namespaces, and applies default network policies and resource quotas to them). Each namespace might be labeled with its tenant and zone, and an Azure AD group is mapped to a RoleBinding in that namespace allowing devs to manage their own deployments.
- Cross-namespace access is denied by default (no dev should create ClusterRole that spans beyond their scope - we guard that via reviews and maybe via OPA policies that prevent privilege escalation attempts).
- If one team’s app needs to talk to another’s, we treat it like an external API dependency (go through network controls and explicit allow policies).
DevOps Integration: Azure DevOps Pipelines will also be used to automate security checks (like code scanning, image vulnerability scanning). For example, after building container images, we can integrate a scanner (Azure Security Center or Trivy) to check for vulnerabilities. Only if the image passes policies (no critical vulns) do we proceed to deployment. This ties into compliance (supply chain security which NIS2 emphasizes in terms of assessing supplier vulnerabilities17 ). The results can be tracked for audits (e.g., we can show every image running was scanned and accepted).
In summary, the GitOps approach significantly enhances auditing and reproducibility. Every change is in Git (with commit history linked to user identities), fulfilling a key ISO27001 principle of change logging. Argo CD ensures clusters reflect that known-good state. And by isolating CI from direct deployment, we minimize credentials spread (Azure DevOps doesn’t need to store a Kubeconfig/token - Argo uses a Kubernetes ServiceAccount token only internally). This reduces secrets management overhead and prevents a compromised CI from directly altering the cluster - it would still need to push to Git which is monitored.
Identity and access management¶
Access to both the Azure environment and the AKS cluster is managed through Azure Active Directory (AAD), enforcing centralized identity controls like Multi-Factor Authentication (MFA) and Privileged Identity Management (PIM). The model ensures that users and service principals only get the minimal rights needed (principle of least privilege) and that any elevation (to admin roles) is time-bound and approved.
Azure RBAC for azure resources¶
All Azure resources (subscriptions, resource groups, etc.) use Azure RBAC with AAD identities:
- Role Separation: We define custom Azure roles or use built-ins to segregate duties. For example, the team that manages the underlying infra (platform engineers) might have Contributor rights on the resource group containing AKS and network, but application developers would have no direct Azure rights there. Instead, developers interact with the cluster via Kubernetes RBAC, not Azure. We might grant developers Reader access on the resource group so they can see logs or diagnostics, but not modify.
- Privileged Roles via PIM: Roles like Owner or User Access Administrator (which grants access permissions) are only assigned via PIM, meaning no one permanently holds those roles. If someone needs to change a key vault policy or network security rule outside of Terraform (in break-glass scenario), they must activate PIM (which requires MFA and logs an audit). Similarly, our AAD admin group for AKS (set in cluster config) is a PIM-controlled group - so to become cluster-admin, one must elevate into that AAD group for a limited time. This addresses ISO27001 requirements for controlled privileged access and aligns with NIS2’s emphasis on identity management and authentication 18(e.g., using MFA19).
- Managed Identity for Azure DevOps: The pipelines (running in Azure DevOps) need to deploy infrastructure (Terraform uses an Azure service principal). We utilize an Azure AD service principal or Managed Identity for the Azure DevOps Service Connection. That principal is granted least-privilege roles (e.g., a custom role that can create the specific resource types needed) on the subscription or resource group. This ensures the CI pipeline itself cannot, say, delete random resources - only what it’s intended to manage.
Kubernetes Access¶
As configured, AKS trusts Azure AD for user authentication. When a developer or admin wants kubectl access, they must az aks get-credentials which under the hood gets an AAD token. We have set up:
AAD Groups Mapping:
- AKS-Admins - members of this group have full admin rights on the cluster. We mapped this group’s object ID in the AKS admin_group_object_ids. Only platform admins in PIM have membership in this group.
- Team1-Dev - for developers of Team1, etc. We then create Kubernetes RBAC RoleBindings that bind, for example, the Team1-Dev AAD group to a Role in the team1-dev and team1-prod namespaces. The Role could be something like edit/developer role (ability to create pods, services, etc., but not affect other namespaces or cluster-scoped resources).
- Platform-SRE - an ops team group that might have broader read access, maybe cluster-wide read and ability to view all namespaces for troubleshooting, but not write in app namespaces unless emergency. Using AAD groups means as people join/leave teams, our IT can just update group membership and it reflects in cluster access immediately (no need to separately manage Kubernetes users).
-
K8s Role Definitions: We define cluster roles and namespace roles as needed:
-
A read-only role for auditors (they can list all resources but not modify).
- A developer role per namespace (can create/edit deployments, pods, configmaps, etc. within namespace).
- A restricted role for DORA teams which give allowed access to exec into pods with approval, etc. These are all applied as YAML via GitOps (Argo CD has an app for “platform-rbac” which contains these Role and RoleBinding manifests). This way the definitions are also code-reviewed. Example:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: dev-role
namespace: team1-dev
rules:
- apiGroups: ["", "apps", "extensions"]
resources: ["deployments", "pods", "services", "configmaps", "secrets"]
verbs: ["get", "list", "watch", "create", "update", "delete"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: dev-binding
namespace: team1-dev
subjects:
- kind: Group
name: "Team1-Dev" # AAD group display name
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: dev-role
apiGroup: rbac.authorization.k8s.io
We replicate similar in team1-prod namespace.
- DORA team elevated privileges: If DORA compliance requires that certain sensitive operations be double-checked, we might integrate with Azure AD PIM such that even if a developer has access to their namespace, to perform a production deployment they require an approval. This can be out-of-band (a change management process) or we could enforce it via pipeline gates. For example, even after Argo CD syncs, maybe a human needs to approve the new version for a DORA-tagged app (this is more of process than tech, but we note it).
- Service Identities: Applications themselves often need to call Azure APIs (Key Vault, SQL, etc.). We leverage Azure AD Workload Identity for AKS. This is a newer approach that avoids the old AAD Pod Identity’s overhead. We enabled oidc_issuer on AKS, which gives us an OIDC endpoint. For each application that needs Azure access, we create an Azure AD Managed Identity (User-assigned). Then we create a federated identity mapping linking that MI with the Kubernetes Service Account used by the app. For instance, Team1’s API app runs with service account team1-api-sa in namespace team1-prod. We federate that with the managed identity Team1API-MI so that when the pod requests a token from AAD (via the OIDC token projected by K8s), AAD will trust it and give an access token for the managed identity. This way, the pod can access Azure resources (Key Vault secrets, or SQL DB) as that managed identity, without any password/secret. We give that MI limited permissions: e.g., Key Vault Secret User on the team’s Key Vault (can get secrets), and db_datareader on their specific database (through an AAD group assignment in SQL). This satisfies the requirement that no hard-coded credentials are in pods and that secrets are managed securely.
Example: The Terraform for a federated identity could not be fully done in azurerm provider at time of writing (it’s evolving), but conceptually:
resource "azurerm_user_assigned_identity" "team1_api" {
name = "team1-api-mi"
resource_group_name = azurerm_resource_group.spoke.name
location = azurerm_resource_group.spoke.location
tags = { "Owner" = "Team1", "Purpose" = "AccessKeyVault" }
}
# Grant this MI access to Key Vault and SQL (outside this snippet)
# Federated identity:
resource "azuread_application_federated_identity_credential" "team1_api_fic" {
application_object_id = azurerm_user_assigned_identity.team1_api.principal_id
display_name = "team1-api-aks-federation"
audiences = ["api://AzureADTokenExchange"]
issuer = azurerm_kubernetes_cluster.aks.oidc_issuer_url
subject = "system:serviceaccount:team1-prod:team1-api-sa"
}
Now the service account in Kubernetes named “team1-api-sa” in namespace “team1-prod” is tied to that identity. In the workload’s deployment YAML, we add annotation like:
serviceAccountName: team1-api-sa
annotations:
azure.workload.identity/client-id: <client id of the team1-api-mi>
This triggers the webhook to project a token. The app can then use Azure SDK or curl with managed identity endpoint to get a token for Key Vault. All without a secret. This addresses both security and compliance (no sharing of passwords, and we can audit which identity accessed Key Vault).
Azure key vault integration¶
Each team (Standard or DORA) gets one or more Azure Key Vaults for secret storage. We choose to have at least one vault per team per environment (to isolate secrets). For example, kv-team1-prod holds production secrets for Team1’s apps. This vault is set with Private Endpoint in the network, and publicNetworkAccess is disabled (so it’s not reachable from internet). Only the private link (and Azure services via trusted services if needed) can reach it. The Key Vault stores things like: DB connection strings (if not using MSI auth), API keys for third-party, TLS certificates for the team’s custom domains, etc.
Access Control on Key Vault: We use Azure RBAC for Key Vault or Access Policies to ensure only the appropriate identities can read specific secrets:
- The application’s managed identity as above can read its needed secrets (only secret scope, not keys/certs unless needed).
- Developers might have Reader access to secrets in dev environment vaults (to troubleshoot), but for prod vault, maybe only the app and perhaps a break-glass admin can read (to prevent developers from seeing prod secrets in plain text - aligning with principle of least privilege). Instead, their app fetches it at runtime.
- Azure DevOps pipelines often need to retrieve secrets (e.g., a database password for migration script). For that, we either give the pipeline’s service principal access to needed secrets or better yet, use the pipeline’s system-managed identity (if running self-hosted agent on an Azure VM, it can use a managed identity to fetch secrets directly). Alternatively, use Azure DevOps’s built-in secret mechanism to retrieve from Key Vault at job runtime (it has a Key Vault integration too).
Secret Delivery to AKS: Two methods are common: 1. External Secrets Operator: As mentioned, we deploy an operator that can sync secrets. We create an ExternalSecret resource in K8s referencing the vault and secret name. The operator (with its own managed identity that has KV access) will create a Kubernetes Secret. Advantage: app reads from regular Kubernetes Secret (fast local read, easier integration), and the operator keeps it updated if it changes. Disadvantage: secrets exist in etcd (though they can be encrypted at rest via AKS managed keys). 2. Direct Use in App: App uses the Azure SDK to fetch from Key Vault when needed. This is secure and avoids storing in etcd, but requires code logic. For config values needed at start-up, many prefer having them already in environment (which ExternalSecrets provides via filling a Secret and then env var).
We may choose ExternalSecrets for things like DB connection strings so that if the DB password rotates, operator can update the secret and pod can automatically reload (with some help). For extremely sensitive things that we don’t even want to land in etcd, apps can fetch on startup and only hold in memory.
Key vault with private link example
resource "azurerm_key_vault" "team1" {
name = "kv-team1-prod"
resource_group_name = azurerm_resource_group.spoke.name
location = azurerm_resource_group.spoke.location
tenant_id = data.azurerm_client_config.current.tenant_id
sku_name = "Standard"
soft_delete_retention_days = 90
purge_protection_enabled = true
public_network_access_enabled = false
network_acls {
default_action = "Deny"
bypass = "AzureServices"
}
tags = {
"Team" = "Team1"
"Environment" = "Prod"
}
}
resource "azurerm_key_vault_access_policy" "team1_app" {
key_vault_id = azurerm_key_vault.team1.id
tenant_id = data.azurerm_client_config.current.tenant_id
object_id = azurerm_user_assigned_identity.team1_api.principal_id
secret_permissions = ["get", "list"]
}
resource "azurerm_private_endpoint" "team1_kv_pe" {
name = "pe-kv-team1-prod"
resource_group_name = azurerm_resource_group.spoke.name
location = azurerm_resource_group.spoke.location
subnet_id = azurerm_subnet.private_endpoints.id
private_service_connection {
name = "kv-team1-connection"
private_connection_resource_id = azurerm_key_vault.team1.id
subresource_names = ["vault"]
}
}
After this, we also need to create a Private DNS Zone privatelink.vaultcore.azure.net with an A record for kv-team1-prod.vaultcore.azure.net pointing to the private IP of the PE. Terraform can do that as well. We repeat similar for other vaults, ACR, and SQL.
With Key Vault in place, developers store secrets via Azure DevOps pipeline tasks or scripts (the pipeline’s Azure identity has setpolicy to write secrets). Or we allow a select few to use Azure Portal/CLI to update secrets (with PIM). Every secret is tagged or named clearly, and ideally we maintain a Secrets Inventory mapping which app uses which secret - aiding risk assessments required by ISO27001. The Key Vault has diagnostic logging to Log Analytics turned on, so any access (get secret) is logged (we can see if an identity tried incorrect secret names, etc., which could indicate a misconfig or malicious attempt).
Azure SQL database¶
For persisting relational data, we use Azure SQL Database (PaaS) for each team’s services that require it. For multi-tenancy and compliance:
- Each team gets a separate SQL logical server (or at least separate database) to prevent any chance of one team accessing another’s data. For DORA-regulated data, likely a separate server with stricter network controls.
- Private Endpoint: As with other services, we create a private endpoint for the SQL server (\<servername>.database.windows.net) in the network. We disable public network access on the SQL server (so it only listens via private link). This means all database connections from AKS will go through the VNet.
- Authentication: We enable Azure AD authentication on the SQL server. We set an AAD admin group for the server (e.g., a DBA or ops group). The applications themselves use their managed identity to authenticate to the database - no password. This is done by creating AAD contained users in the database: e.g. CREATE USER [team1-api-mi] FROM EXTERNAL PROVIDER; and then granting it appropriate roles (db_owner for simplicity in dev, but in prod maybe a custom role that allows DML but not DDL if we want to restrict schema changes outside migrations). For now, assume the app MI is given db_datareader/write roles needed. The Azure SQL will trust tokens from that managed identity. This way, even if someone got hold of the connection string from the app, they can’t connect without the MI’s token (which only that app can get).
- Compliance settings: TDE (Transparent Data Encryption) is on by default. For extra compliance, we can use a customer-managed key in Key Vault for TDE (so that if needed we can revoke keys). We also enable SQL Auditing: logs of queries and logins can be sent to Log Analytics or storage. This might be required for certain regulations to detect misuse of data. We at least turn on auditing for failed logins and permission changes. We also enable Advanced Threat Protection on SQL (to alert on anomalous queries, SQL injection attempts). These logs flow into Sentinel as well, creating a comprehensive security monitoring.
- Performance & HA: If needed, for resilience (DORA) we could use SQL geo-replication to another region. But that’s a broader DR strategy call. At minimum, Azure SQL has high availability within region. We also schedule regular exports or use Point-in-Time Restore ability for backup.
Azure SQL with private endpoint example¶
resource "azurerm_mssql_server" "team1" {
name = "team1-sqlsvr-prod"
resource_group_name = azurerm_resource_group.spoke.name
location = azurerm_resource_group.spoke.location
version = "12.0"
administrator_login = "sqladminuser" # only for legacy admin, not heavily used
administrator_login_password = random_password.sqladmin.result
minimum_tls_version = "1.2"
public_network_access_enabled = false
azuread_administrator {
login = "Team1-DBAdmins"
object_id = azuread_group.team1_db_admins.object_id
tenant_id = data.azurerm_client_config.current.tenant_id
}
tags = { "Team" = "Team1", "Environment" = "Prod" }
}
resource "azurerm_mssql_database" "team1db" {
name = "Team1AppDB"
server_id = azurerm_mssql_server.team1.id
sku_name = "GP_Gen5_2" # General Purpose, 2 vCores as an example
zone_redundant = false
collation = "SQL_Latin1_General_CP1_CI_AS"
tags = { "Team" = "Team1", "Environment" = "Prod" }
}
// Private Link for SQL
resource "azurerm_private_endpoint" "team1_sql_pe" {
name = "pe-sql-team1-prod"
resource_group_name = azurerm_resource_group.spoke.name
location = azurerm_resource_group.spoke.location
subnet_id = azurerm_subnet.private_endpoints.id
private_service_connection {
name = "sqlserver-pl"
private_connection_resource_id = azurerm_mssql_server.team1.id
subresource_names = ["sqlServer"]
}
}
After this, we’d add an azurerm_private_dns_zone for privatelink.database.windows.net and an A record like team1-sqlsvr-prod.privatelink.database.windows.net ->
Using Managed Identity in App: The connection string in app config would be like: Server=tcp:team1-sqlsvr-prod.database.windows.net,1433;Database=Team1AppDB;Authentication=Active Directory Managed Identity; - meaning no user/password, use MSI. The app just opens connection using an AAD token under the hood (most drivers support this). We’ll ensure the connection policy of SQL server allows Azure AD (which it does since we set an AAD admin).
Data Access Governance: Using AAD for DB means one could even directly give certain AAD users read access to the database for BI or support, without sharing passwords. All access attempts can be audited in the SQL audit logs with their AAD email. This is a big plus for compliance and investigations.
Multitenancy: Because each team’s DB is isolated, there’s no risk of cross-team data leakage at the DB level. Even within a team, they might choose multiple DBs for different apps, but that’s their design choice.
Tags and Inventory: We tag databases with team and env, allowing easy queries of all prod DBs for compliance checks (DORA might require an inventory of all critical assets and data stores).
Logging, monitoring, and auditing¶
Robust logging and monitoring are built into the platform to satisfy operational needs and compliance (e.g., NIS2’s requirement for logging incidents and monitoring systems). The strategy is multi-faceted:
- Azure Monitor & Log Analytics: Azure resources (AKS control plane, App Gateway, Firewall, Key Vault, SQL) send diagnostic logs to a central Log Analytics workspace. We then enable Azure Sentinel on that workspace to provide SIEM capabilities: correlation rules, incident detection, and response workflows. For example, Azure AD sign-in logs, Azure Firewall logs, and AKS audit logs all go into Sentinel, where we set up alerts like “Multiple failed Kubernetes API auth attempts” or “Firewall denied connection to known malware IP” to notify security staff. These are directly supporting compliance as both ISO27001 and NIS2 require proactive threat detection and incident reporting.
-
AKS Cluster Logs:
-
Audit Logs: We turn on Kubernetes audit logging (an AKS feature) which records every call to the API server (create pod, delete secret, etc.). These logs are shipped to Log Analytics (by enabling the AKS monitoring addon or via Azure Diagnostic Settings on the cluster resource). They can be queried and also ingested by Sentinel. This is important for forensic analysis - if an unauthorized change happened, we can trace it.
- Node & Pod Logs: We rely on Datadog for application logs, but for system logs (like kubelet or systemd logs on nodes), we could enable the Azure Monitor container insights. The new Azure Monitor agent (AMA) can be configured to collect stdout/stderr of all pods (but that might duplicate what Datadog does). Instead, we might let Datadog capture app logs and metrics, and use Prom/Grafana for system metrics. We can keep some baseline logging to Log Analytics, but careful not to double collect. Possibly we restrict container logs to Datadog only (since devs prefer Datadog to search their app logs with nice UI). For AKS cluster events and system messages, Azure Monitor can keep those (like OOM events, etc.).
- Datadog (Application Monitoring): Each application team can define what logs and custom metrics they send to Datadog. Datadog becomes their APM (Application Performance Monitoring) tool - tracking traces, requests, etc. We ensure the Datadog agent has necessary permissions (API key and network access). In a regulated setting, Datadog SaaS might need to be approved as a processor of data - we ensure it does not get PII or sensitive data (developers should avoid logging sensitive info, or use encryption/truncation). If data residency is a concern, Datadog EU site is used (which we allow egress to). If Datadog isn’t allowed, an alternative could be self-hosted ELK stack, but that’s heavy to maintain - not preferred in a managed platform spec or Application Insight, which reside the data in the same cloud as AKS.
- Prometheus & Grafana (Infrastructure Monitoring): Prometheus scrapes metrics from Kubernetes (via kube-state-metrics) and from apps (if they expose /metrics). We set some recording rules for key metrics (CPU, memory usage per namespace, error rates). Grafana dashboards are set up for cluster health (one for showing each node pool utilization, one for showing network traffic, etc.). This helps Operations and also can feed into capacity management - e.g., if DORA team’s restricted pool is 80% utilized consistently, we plan to scale it or add nodes. Grafana is configured with Azure AD auth so that team members can view relevant dashboards (possibly multi-tenant - though Grafana itself doesn’t isolate data by tenant easily, we rely on the honor system or separate dashboards per team).
-
Alerting:
-
For infrastructure: Azure Monitor alerts on critical conditions (node down, pod crash looping beyond threshold, CPU saturated) can either be set or we use Datadog/Prometheus alerts. Datadog might handle app-level alerts (like high latency, errors) since devs look there. Prometheus can fire alerts to Alertmanager (which we could configure to send Teams/Slack notifications to ops). Cloudops can monitor and alert AKS through azure metrics.
- Security alerts: Sentinel is used for security alerts (which should alert the SOC). For example, if someone tries to access a Key Vault secret and is denied, that log could trigger an alert if it looks malicious. Sentinel’s use also helps with DORA’s incident reporting - we can quickly gather evidence from logs for any security incident and also demonstrate regular monitoring to regulators.
-
Audit and Compliance Logging: We maintain an audit trail of changes:
-
Git history (with PR comments) shows the who/when/what of infra changes.
- Azure AD logs show who accessed what (PIM activations, etc.).
- Kubernetes RBAC audit: we could use OPA Gatekeeper’s audit function to regularly report any violations of policy or any broad permissions in the cluster.
- The platform can periodically run configuration compliance scans (maybe via Azure Policy or scripts) to ensure things are as expected (e.g., ensure all Key Vaults have soft delete on, all Storage accounts (if any) have encryption, etc.). Many of these checks are enforced by policy at creation, but continuous compliance is good to verify.
Best Practices:
- Retention: Log Analytics by default might retain 30-90 days. For compliance, we may need to retain audit logs 6 months or more. We configure Sentinel’s workspace to retain data for at least 180 days (DORA might require a certain period for incident evidence retention). Alternatively, export logs to an Archive storage for long-term. Key Vault and AKS audit logs especially should be kept long enough to support any investigations.
- Separation of duties: Only security team has full access to Sentinel (so dev teams can’t delete incidents). Dev teams have access to Datadog and limited Grafana, but not to raw logs in Sentinel unless allowed. This ensures that if a dev account is compromised, the attacker cannot easily cover their tracks in Sentinel.
- Testing monitoring: We will test the monitoring by generating dummy events (e.g., have a test pod try to connect to a banned IP to see if firewall logs it and Sentinel alert triggers). Regular drills like this ensure our alert rules and log pipeline works - an expectation in regulatory compliance to verify controls effectiveness2021.
Terraform Example - Diagnostic Settings: For each resource type, we can define diagnostic settings to send logs to Log Analytics. Example for Application Gateway:
resource "azurerm_monitor_diagnostic_setting" "appgw_diagnostics" {
name = "appgw-diag"
target_resource_id = azurerm_application_gateway.ingress_waf.id
log_analytics_workspace_id = azurerm_log_analytics_workspace.sentinel_ws.id
logs {
category = "ApplicationGatewayAccessLog"
enabled = true
retention_policy { enabled = false }
}
logs {
category = "ApplicationGatewayFirewallLog"
enabled = true
}
logs {
category = "ApplicationGatewayPerformanceLog"
enabled = false
}
metrics {
category = "AllMetrics"
enabled = true
retention_policy { enabled = false }
}
}
We’d do similar for Azure Firewall (categories: AZFWNetworkRule, AZFWApplicationRule, etc.), for Key Vault (VaultAuditLogs), for SQL (DevOps might use PowerShell as some older resources not fully in Terraform). Also for the AKS resource, though if we use container insights, it auto-configures some.
Datadog Integration: This is likely configured with a helm chart for the Datadog agent. We store the Datadog API key in Key Vault and feed it as a Kubernetes Secret via pipeline. In values, we set logsEnabled: true, kubeStateMetricsEnabled: true etc. That installation itself can be managed by Argo CD as part of platform stack.
Grafana: Using Azure Managed Grafana, Terraform can set it up and assign RBAC roles it integrates with AAD for auth so user groups see certain folders. Managed Grafana can read from Log Analytics and from Azure Monitor metrics as well, which could be neat for a single pane.
Data Protection: Finally, note that all logs and data are within Azure (Sweden Central region for primary storage) fulfilling any data residency concerns. Datadog is external (so ensure no sensitive data flows there if that’s a concern, or get approval for it with proper DPA).
Additional governance and compliance measures¶
Beyond architecture and config, we implement governance to keep the platform secure over time:
-
Azure Policy: We assign a set of Azure Policies to the subscription/resource groups to prevent drift from our intended security posture. For example:
-
Deny creation of any public IPs or public load balancers outside of our approved gateway. (So a developer with Contributor rights somewhere can’t create a bypass).
- Require that any new storage accounts or databases have private endpoints (ensuring future resources follow suit).
- Enforce tagging: all resources must have tags like DataClassification or Owner. This is useful if later an auditor wants to see which resources hold customer data (we tag those appropriately).
- Policies for Key Vault: require soft-delete and purge-protection on (which we did via Terraform, but policy is a safety net if someone manually creates a vault). These policies are defined in code (possibly using Azure Policy as Code with JSON definitions in a repo and deployed via terraform or Azure DevOps).
- Burton Model Validation: Periodically, we review the network flows and compare with the Burton model guidelines. E.g., verify that no restricted zone node has any open path to internet; verify that semi-trusted zone (gateway) cannot directly reach databases, etc. We update network policies or NSGs if any gap is found.
- DORA-specific: DORA also expects incident response plans and continuity plans. While procedural, our platform aids this by supporting rapid redeploy and having all infra codified. We document recovery steps (how to rebuild in new region from code, how to restore databases from backups). We also ensure regular backup testing: Key Vault secrets and SQL databases backups are tested (a Key Vault can be recovered in a sandbox to ensure we can retrieve all keys, a database point-in-time restore is done quarterly to verify backup integrity). These tasks can be automated with scripts triggered by pipeline and results logged. It shows regulators we proactively ensure resilience (which DORA stresses via continuous testing2223).
- Training and Usage: Development teams are trained on using GitOps (no manual kubectl on prod) and on writing manifests that comply with our policies (we provide templates to reduce trial and error). Also, teams have to follow our onboarding checklist (e.g., classify their data, ensure their app has proper health probes for monitoring, etc.).
Common Pitfalls: We maintain documentation of pitfalls and how to avoid them:
- Private Link DNS issues (and the solution).
- The need to coordinate NSG, NetworkPolicy, and Istio rules (mistakes here can lead to outages or open holes - e.g., if someone adds a broad allow all networkpolicy in their namespace it could undermine isolation; we mitigate by reviewing such changes and possibly restricting who can create NetworkPolicy objects).
- Upgrading AKS: We pin a minor version but will patch regularly. Upgrades are done via Terraform (changing the version and applying). One must ensure all node pools are upgraded in a controlled sequence (system first, then others) and monitor. If not careful, mismatched versions can cause issues. We plan maintenance windows for cluster upgrades, and test them in a staging environment cluster first.
- Istio version compatibility: We keep Istio updated (using Argo to pull new charts), as outdated service mesh could be a risk. The platform team monitors CVEs in components (Istio, Argo, etc.) and patches accordingly, demonstrating proactive security maintenance (which is good for ISO and NIS2).
- Tags and Metadata: We use tagging not just for cost, but for tracking compliance scope. For example, tag Compliance=DORA on any resource related to the DORA in-scope systems. This allows generating a view of all components that must meet DORA controls. It’s helpful for audits, as we can filter logs or inventories by this tag to answer auditors about in-scope assets.
- Documentation: This spec itself would be an evolving internal document. We keep network diagrams current 24(update if topology changes), and record data flows25 as required. Whenever architecture changes (new service, etc.), we assess compliance impact and update docs.
Conclusion¶
The proposed AKS-based platform provides a secure-by-design, compliant, and automated environment for containerized workloads. By leveraging Azure’s managed services with additional hardening (private networking, WAF, Firewall) and adopting GitOps and IaC, we achieve a high degree of control and consistency.
This design directly supports ISO 27001 objectives by implementing access control, network security, and logging controls; it aligns with NIS2 by enhancing risk management (through segmentation, MFA, supply chain security via IaC) and ensuring rapid incident detection ; and it positions the organization to meet DORA requirements for operational resilience by having robust continuity plans (Infrastructure as Code + monitoring) and strict ICT risk management (controlled changes, tested failovers)2627.
By segregating teams and enforcing multi-tenancy guardrails, we allow different projects (including those under financial regulations) to safely coexist, each with appropriate security per their needs. The heavy use of automation (Terraform, Argo CD) means the platform is also highly maintainable - changes are easier to apply and audit, and scaling out to new teams or even new regions is repeatable.
Going forward, continuous improvement will involve refining policies (e.g., adapting to new threats or compliance updates), performing regular security audits, and possibly integrating new Azure capabilities (like Azure Container Registry content trust, or Azure Defender for Kubernetes for runtime threat detection) to further enhance the platform. The foundation laid out in this specification ensures that such improvements can be integrated in a structured and reliable manner, with the baseline requirements of security, compliance, and reliability always in focus.
Acronym list¶
| Acronym | Meaning |
|---|---|
| AAD | Azure Active Directory |
| ACR | Azure Container Registry |
| AD | Active Directory |
| AGIC | Application Gateway Ingress Controller |
| AKS | Azure Kubernetes Service |
| AMA | Azure Monitor Agent |
| API | Application Programming Interface |
| ARM | Azure Resource Manager |
| Argo CD | Argo Continuous Delivery |
| CI | Continuous Integration |
| CI/CD | Continuous Integration / Continuous Deployment |
| CNI | Container Network Interface |
| CPU | Central Processing Unit |
| CSP | Cloud Service Provider |
| DB | Database |
| DMZ | Demilitarized Zone |
| DNS | Domain Name System |
| DORA | Digital Operational Resilience Act |
| DR | Disaster Recovery |
| FQDN | Fully Qualified Domain Name |
| GPU | Graphics Processing Unit |
| IaC | Infrastructure as Code |
| ILB | Internal Load Balancer |
| IP | Internet Protocol |
| Istio | An open-source service mesh that layers transparently onto existing distributed applications |
| JSON | JavaScript Object Notation |
| KV | Key Vault |
| MI | Managed Identity |
| MFA | Multi-Factor Authentication |
| MSI | Managed Service Identity |
| mTLS | Mutual TLS (Transport Layer Security) |
| NSG | Network Security Group |
| OPA | Open Policy Agent |
| OWASP | Open Worldwide Application Security Project |
| PaaS | Platform as a Service |
| PE | Private Endpoint |
| PIM | Privileged Identity Management |
| PSP | Pod Security Policy |
| RBAC | Role-Based Access Control |
| SaaS | Software as a Service |
| SIEM | Security Information and Event Management |
| SQL | Structured Query Language |
| SRE | Site Reliability Engineering |
| SOPS | Secrets OPerationS (tool for managing secrets) |
| SSH | Secure Shell |
| TLS | Transport Layer Security |
| UDR | User Defined Route |
| VM | Virtual Machine |
| VNet | Virtual Network |
| VPN | Virtual Private Network |
| WAF | Web Application Firewall |
| YAML | YAML Ain’t Markup Language (used for config files) |
-
https://nis2directive.eu/nis2-requirements/#:~:text=To%20comply%20with%20the%20new,better%20access%20control%2C%20and%20encryption ↩
-
https://www.pwc.com/mt/en/publications/technology/dora.html#:~:text=%2A%20Set,the%20impact%20of%20ICT%20risk ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=flowing%20in%20both%20directions%2C%20to,cluster%20that%20hosts%20the%20CDE ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=,the%20virtual%20network%20is%20allowed ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=As%20part%20of%20your%20documentation%2C,There%20are%20some%20specific%20requirements ↩
-
https://nis2directive.eu/nis2-requirements/#:~:text=To%20comply%20with%20the%20new,better%20access%20control%2C%20and%20encryption ↩
-
https://nis2directive.eu/nis2-requirements/#:~:text=a%20security%20incident.%20,security%20level%20for%20all%20suppliers ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=traffic%20from%20within%20the%20virtual,network%20is%20allowed ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=As%20part%20of%20processing%20a,egress%20traffic%20mitigates%20that%20threat ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=,cluster%20communications ↩
-
https://francescomolfese.it/en/2021/05/progettazione-di-architetture-di-rete-sicure-per-azure-kubernetes-service-aks/#:~:text=Gateway%20may%20have%20assigned%20a,The%20WAF%20protects%20the%20application ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=,cluster%20communications ↩
-
https://learn.microsoft.com/en-us/azure/architecture/example-scenario/gitops-aks/gitops-blueprint-aks#:~:text=changes%20to%20a%20Git%20repository,troubleshooting%20scenarios%2C%20you%20can%20grant ↩
-
https://learn.microsoft.com/en-us/azure/architecture/example-scenario/gitops-aks/gitops-blueprint-aks#:~:text=changes%20to%20a%20Git%20repository,troubleshooting%20scenarios%2C%20you%20can%20grant ↩
-
https://argo-cd.readthedocs.io/en/stable/user-guide/best_practices/#:~:text=Best%20Practices%20,source%20code%2C%20is%20highly%20recommended ↩
-
https://nis2directive.eu/nis2-requirements/#:~:text=a%20security%20incident.%20,security%20level%20for%20all%20suppliers ↩
-
https://cwsisecurity.com/5-key-requirements-for-nis2-compliance/#:~:text=Key%20Requirements%20for%20NIS2%20Compliance,to%20Cyber%20Incidents%20%C2%B7%204 ↩
-
https://nis2directive.eu/nis2-requirements/#:~:text=%2A%20The%20use%20of%20multi,security%20level%20for%20all%20suppliers ↩
-
https://nis2directive.eu/nis2-requirements/#:~:text=,policies%20for%20handling%20and%20reporting ↩
-
https://nis2directive.eu/nis2-requirements/#:~:text=,and%20after%20a%20security%20incident ↩
-
https://www.pwc.com/mt/en/publications/technology/dora.html#:~:text=resilience%20to%20ICT,their%20effectiveness%20on%20a%20continuous ↩
-
https://www.pwc.com/mt/en/publications/technology/dora.html#:~:text=The%20essence%20of%20DORA%20is,or%20aspects%20are%20provided%20below ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=As%20part%20of%20your%20documentation%2C,There%20are%20some%20specific%20requirements ↩
-
https://learn.microsoft.com/en-us/azure/architecture/reference-architectures/containers/aks-pci/aks-pci-network#:~:text=As%20part%20of%20your%20documentation%2C,at%20rest%20and%20in%20transit ↩
-
https://www.pwc.com/mt/en/publications/technology/dora.html#:~:text=resilience%20to%20ICT,their%20effectiveness%20on%20a%20continuous ↩
-
https://www.pwc.com/mt/en/publications/technology/dora.html#:~:text=The%20essence%20of%20DORA%20is,or%20aspects%20are%20provided%20below ↩